
Article by: Lazar Nikolov, Ben Coe
最低限の製品(MVP)と本番対応のアプリを分けるものは、磨き込み、最終調整、そしてパレートの法則でいう「最後の20%」の作業です。ほとんどのバグ、エッジケース、パフォーマンス問題は、リリース後に実ユーザーがあなたのアプリケーションを使い込むようになって初めて表面化します。これを読んでいるということは、おそらく作業の80%地点にいて、残りに取り組む準備ができているはずです。
本記事では、アプリケーションのキャッシングを扱います。テールレイテンシの削減、データベースの保護、トラフィックのスパイクへの対処にキャッシュをどう使うか、さらに本番環境で稼働し始めてからそれをどのように監視するかを解説します。
本記事は、MVP を本番環境に持ち込む際に生じる共通の課題を扱うシリーズの一部です。
- 本番環境で大規模データセットをページネーションする:OFFSETの限界とカーソルの利点
- AIによるキャッシング戦略と計測(本記事)
キャッシングのメンタルモデルを構築する
✅ 大半が当てはまるならキャッシュを検討
- 高コスト:CPUが遅い、入出力(I/O)が遅い、DBが重い、大規模な結合/集計、外部API
- 高頻度:呼び出し回数が多い(1分あたりのリクエスト数(RPM)が高い)、またはホットパス上にある(ページ読み込み、コアAPI)
- 再利用可能:同じ入力が繰り返される(キーのカーディナリティが低い)
- ある程度安定:データが毎秒変わらない(または多少の古さを許容できる)
- スパイク負荷:突発的なトラフィックで、キャッシュがアクセス集中(サンダリングハード)を吸収できる
- テールが痛い:P95/P99が悪く、キャッシュミスが遅いリクエストと相関している
- 古いデータを返しても安全:ユーザー影響が小さい、または stale-while-revalidate(SWR)を使える
- 無効化が簡単:TTL(time to live)が機能する、または更新に明確なトリガーがある
- ペイロードが小さめ:メモリコストが妥当で、シリアライズが安い
❌ 次のいずれかに当てはまるならキャッシュしない(または慎重に)
- キーのカーディナリティが高い:ユーザーごと/ページごと/フィルターごとに爆発する → ほとんどがキャッシュミスになる(ページネーションは特殊ケース。後述の注記を参照)
- 変化が激しい:正確性のために鮮度が必須
- 個別対応/権限制御がある:キーのミスでデータ漏えいが起きやすい
- 無効化が難しい:明確なTTLがない、更新が予測できない
- すでに速い:5msの短縮は複雑さに見合わない
- キャッシュスタンピードのリスク:再計算コストが高い+有効期限が同期される(ロック/ジッターが必要)
ページネーションされたエンドポイントをキャッシュする際には特別なルールがあります。まずは1ページ目と一般的なフィルターをキャッシュしてください。1ページ目と少数の一般的なフィルターは通常ホットで再利用されるため、キャッシュの効果が大きくなります。一方、ページ番号が増えるほどキーのカーディナリティが爆発し、再利用は急落します。そのため、深いページは自然にキャッシュミスになりますが、それで問題ありません。全ページで均一なヒット率を達成することではなく、バックエンドの保護と入口(エントリーポイント)でのテールレイテンシ削減を最適化対象にしてください。
本番環境でキャッシング機会を見つける
何をキャッシュすべきかが分かったら、次に考えるべきは「キャッシュが実際に効く場所はどこか」です。本番環境のシステムでは、良いキャッシュ候補はたいてい「痛み」として現れ、通常は3つの形を取ります。
バックエンドでの問題(ここから始めましょう)
バックエンドとフルスタックのシステム において、これが最も手を打ちやすいシグナルです。
注目すべきポイント
- P95/P99 が悪いトランザクション
- DB(データベース)時間が重いエンドポイント
- 繰り返されるクエリ、結合、集計
- ファンアウト(1つのリクエストが多くの下流呼び出しを引き起こす)
- ロック競合、またはコネクションプールの圧力
これらは、キャッシュを利用することで即座に実際の作業を減少させることができるポイントです。
ユーザー影響(確認)
ページの読み込みが遅い、ぎこちないインタラクション、タイムアウト。 Web Vitals のような、Time to First Byte (TTFB)、Largest Contentful Paint (LCP)、および Interaction to Next Paint (INP) などは、バックエンドの遅さが実際にユーザーに影響を与えていることを確認するのに役立ちます。これらは、すでにバックエンドにボトルネックがあると疑った場合に特に有用です。
コスト負担(長期的なシグナル)
ユーザーからまだ不満が出ていなくても、同じ処理の繰り返しはコストになります。
- DB リード(読み取り)ボリュームが高い
- 外部の有料 API 呼び出し
- ロールアップやカウントの再計算
コストはパフォーマンス問題より後から目に見えてくることが多いですが、トラフィックが増えると強い動機になります。
優先順位付けの簡単なヒューリスティックは「コスト密度」です。
1分あたりのリクエスト数 × リクエストあたりの削減時間
ほどほどに遅いが常に叩かれるエンドポイントは、誰も触らない極端に遅いエンドポイントより、たいていキャッシュ対象として適しています。
例: 遅いページネーションのエンドポイント
キャッシュを使わずに重いデータベースクエリを実行している、ページネーションされたエンドポイントを考えてみましょう。
Sentry > Insights > Backend で、(テーブルの上にある)APIトランザクションでフィルタリングすると、次のような状況が見えてきます。
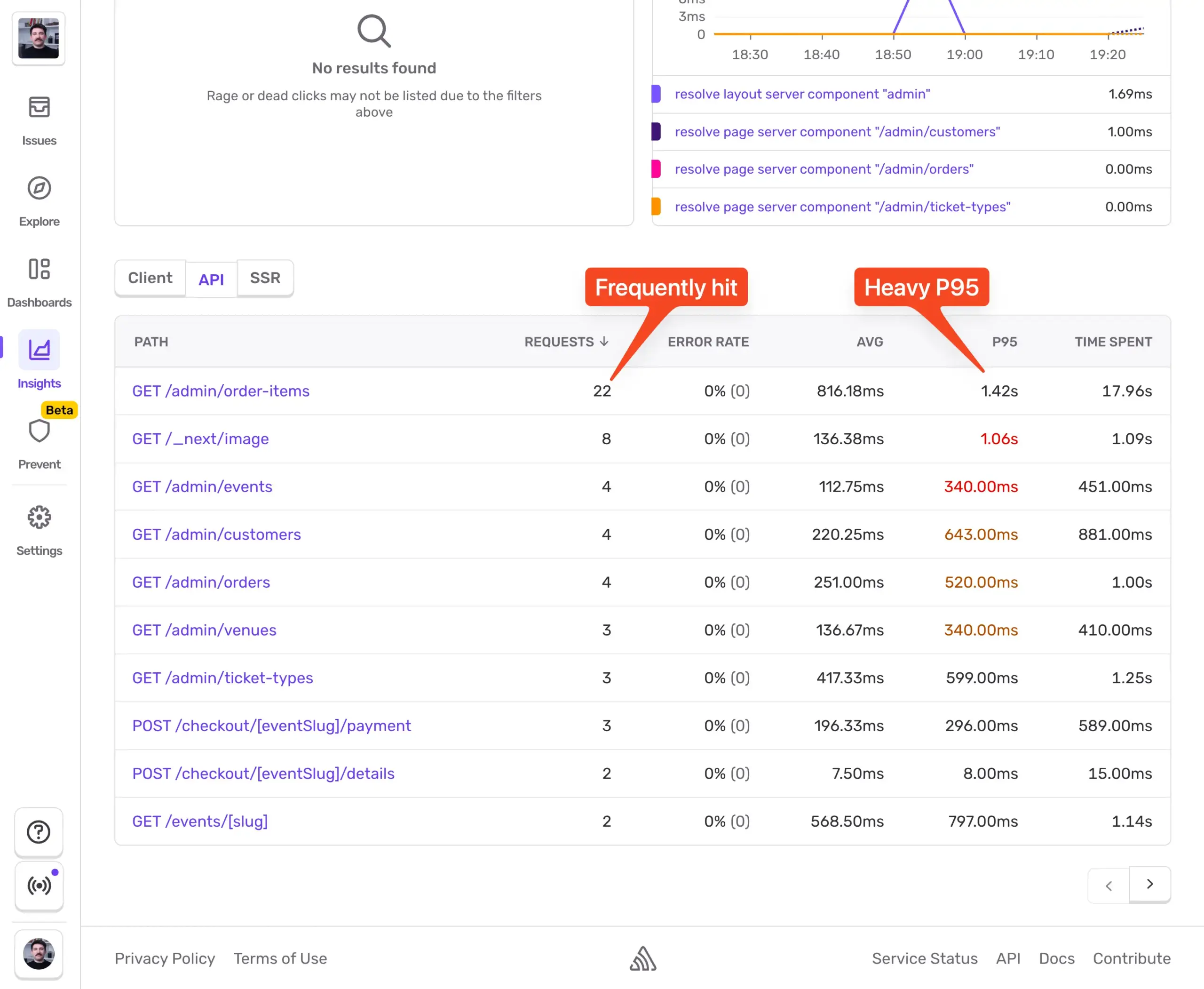
GET /admin/order-items エンドポイントにはキャッシュの余地があります。
詳しく見ていきましょう。
遅いイベントを選び、トレースビューを確認します。
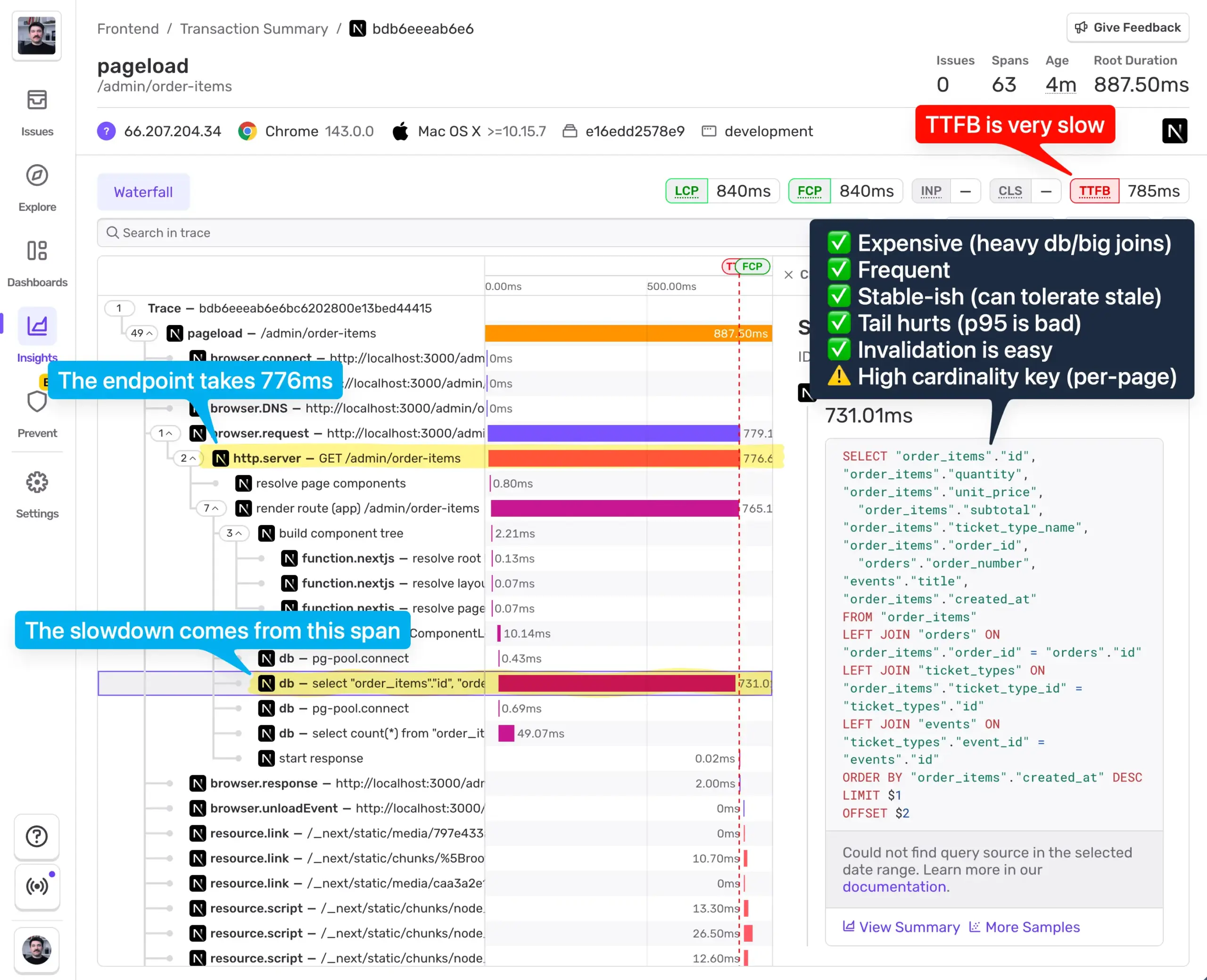
スクリーンショットから、次のことが分かります。
- 合計処理時間は 776ms
- 731ms が単一のDBスパンで消費されている
- 結合が複数ある
- LIMIT + OFFSET によるページネーション
- Web Vitals における TTFB が悪い
チェックリストで確認すると
- ✅ 高コスト(重いDBクエリ、結合)
- ✅ 高頻度(スループットが高い)
- ✅ ある程度安定(短時間の古さを許容できる)
- ✅ テールが痛い(P95が悪い)
- ✅ 無効化が簡単(書き込みがコントロールできる)
- ⚠️ キーのカーディナリティが高い(ページネーション)
これは一括キャッシュではなく、選択的キャッシュに適した強い候補です。
キャッシングの適用と測定
Sentry にはキャッシュモニタリング機能もあります。これにより、アプリケーション全体のキャッシュヒット/ミス率を確認でき、キャッシュがヒットした場合もミスした場合も、本番環境で取得された特定のイベントを調べられます。
キャッシュのインストルメンテーションは、自動と手動の両方で行えます。Redis を使っている場合は自動インストルメンテーションを活用できます。そうでない場合でも、手動でのインストルメンテーションは同じくらい簡単です。
最も手っ取り早い方法は、Seer にやってもらうことです。この記事の公開時点では Seer の「オープンエンドの質問」機能はプライベートアクセスのみですが、少しだけお見せします。Cmd + / でアクセスでき、キャッシュの計装をリクエストできます。
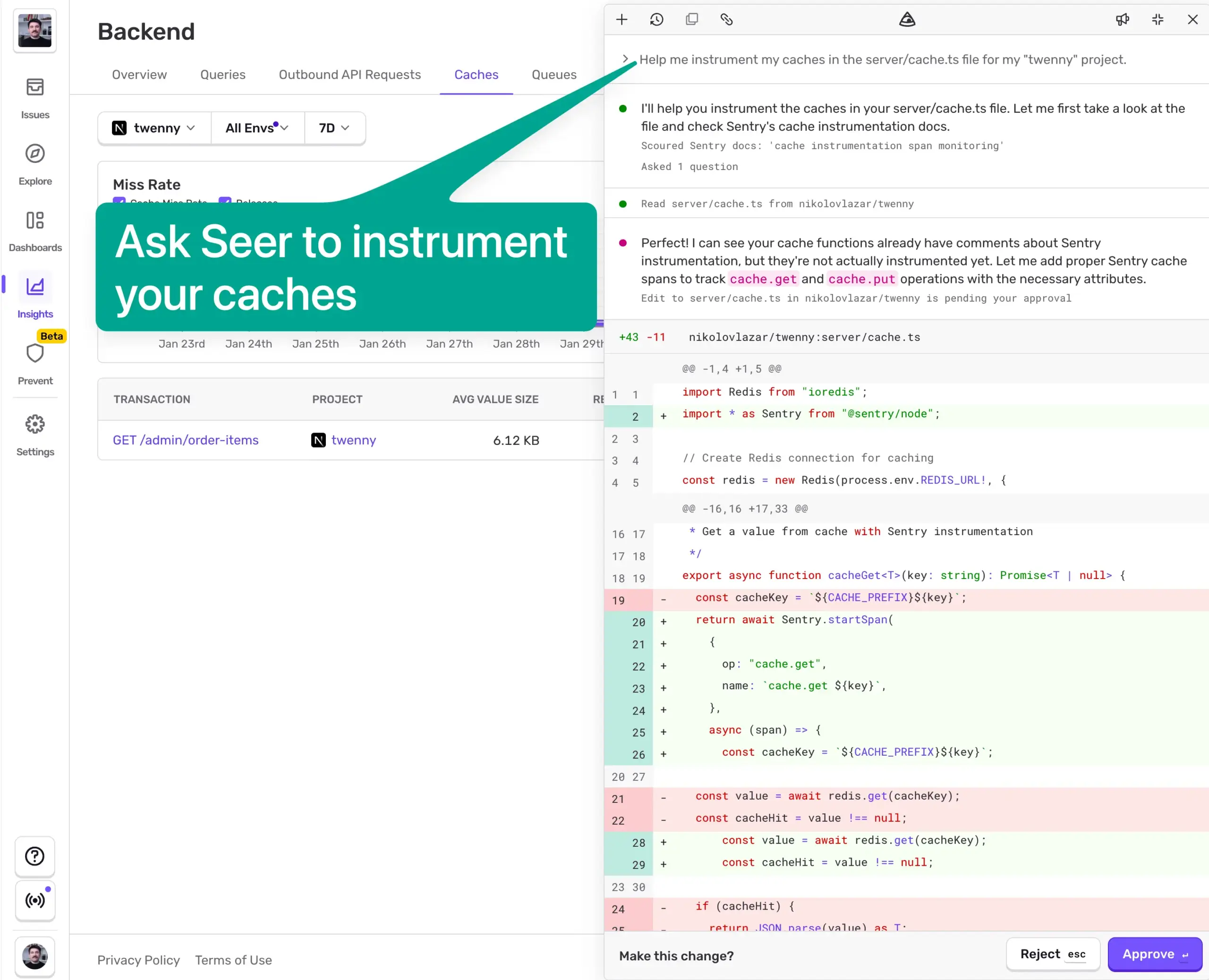
その後、Seer があなたのリポジトリに PR を作成します。あとはマージすれば完了です。
この Seer 機能にまだアクセスできない場合でも、キャッシュをインストルメントするために必要なのは次の手順だけです。
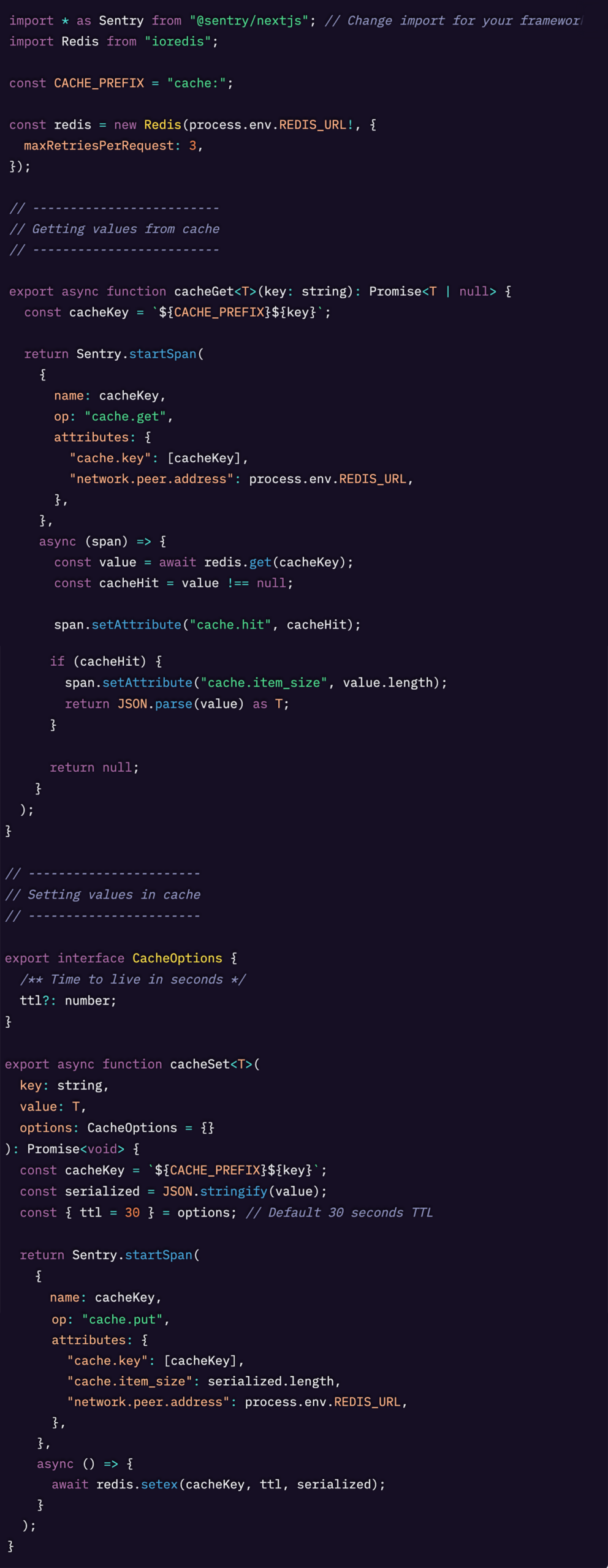
以上です。
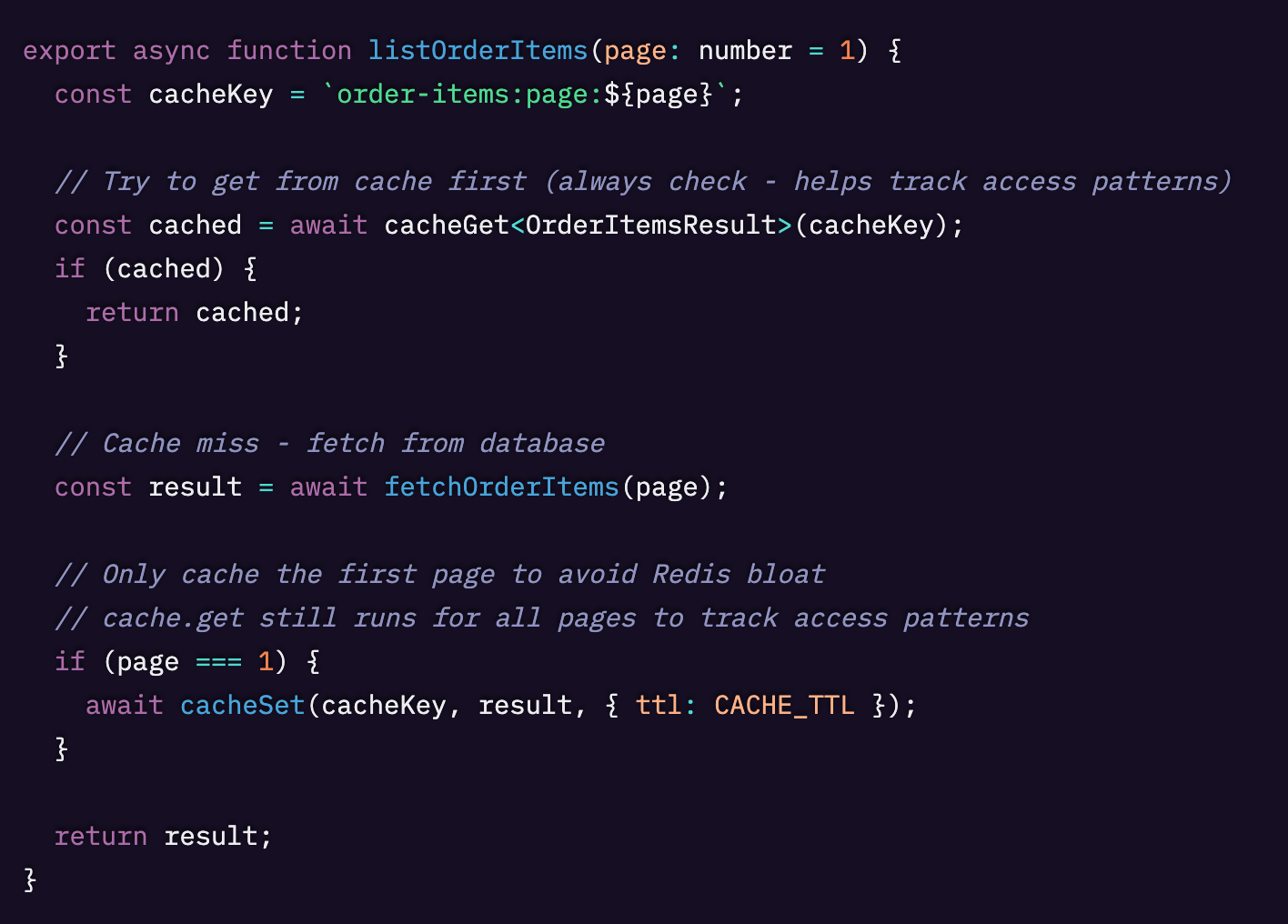
やるべきことは、redis.get と redis.setex を Sentry.startSpan でラップし、キャッシュ専用のスパン属性を付与するだけです。バックエンドで JavaScript を使っていない場合でも、選んだ言語でこれらの関数を書き直せば問題ありません。正しい op と属性を持つスパンを送っている限り、キャッシュのインストルメンテーションは正しく行えます。
これで、次の2つの関数を使えるようになります。
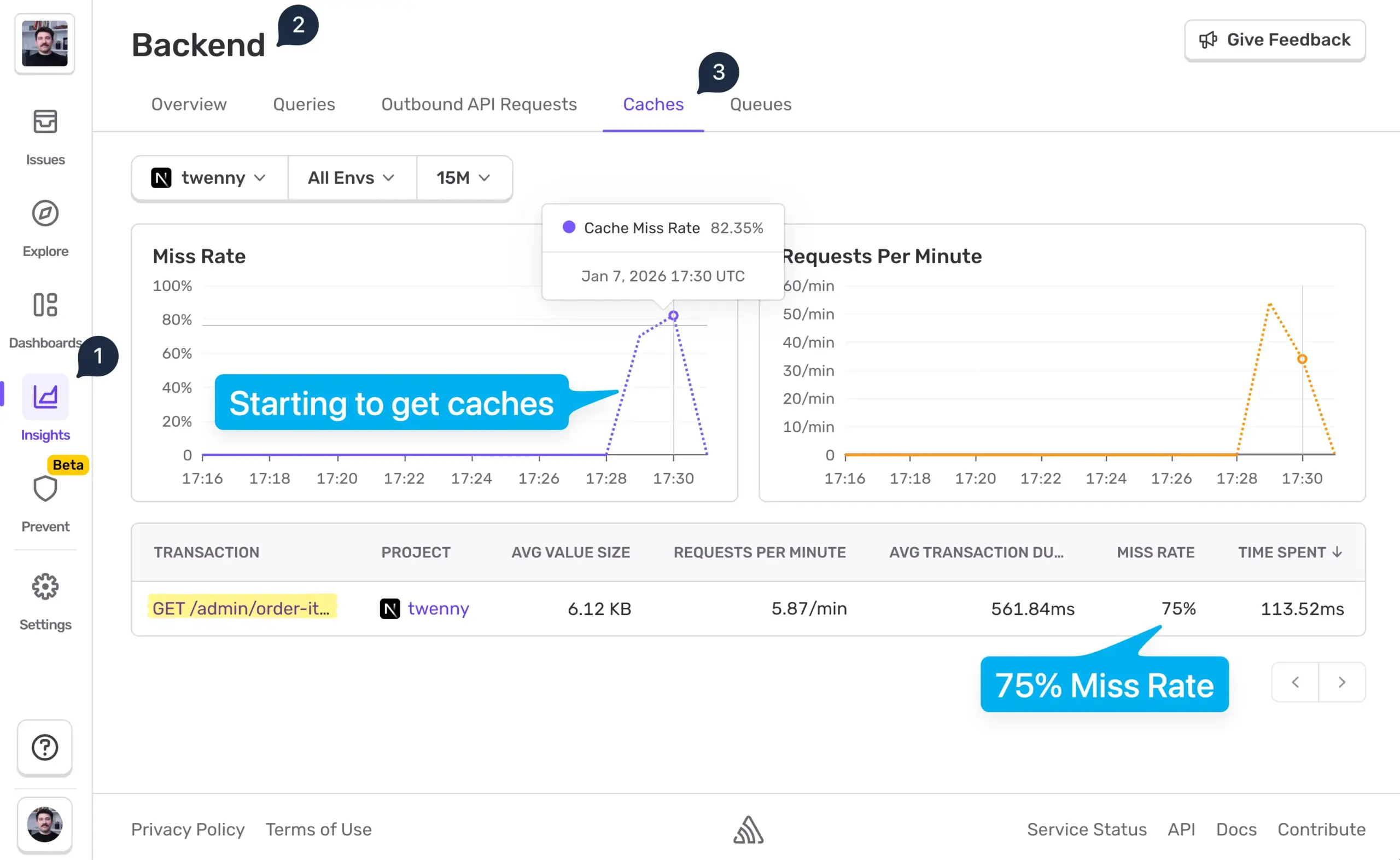
上のスクリーンショットから、キャッシュヒットは1ページ目でのみ発生し、それ以外のページではミスしていることが分かります。これは、ページネーションされたエンドポイントのキャッシュに関するアドバイスどおり、1ページ目と一般的なフィルターだけをキャッシュしているためです。
ユーザーは複数ページを閲覧していましたが、1ページ目が訪問の25%を占めていたため、ミス率が75%になっています。Transaction Duration(トランザクションの継続時間)列を見ると、1ページ目は40ms未満でロードされている一方、他のページではユーザーは700ms超待たされていることが分かります。
つまり、キャッシュ実装はうまく機能しており、ユーザーはページ読み込みの高速化を体感しています。ここから先は、/admin/order-items エンドポイントの通常のミス率が約75%であることが分かります。もし後でバグを入れてしまうと、たとえばキャッシュキーの不具合(パラメータの欠落、余計なパラメータ)、新しいフィルターやソート、ユーザーごと/フラグごとのキーが紛れ込む、キーに変動しやすいデータ(タイムスタンプ、リクエストID、ロケール)を誤って含めてしまう、あるいはTTLを誤る、といったことが起きると、この数値は急上昇し、チャートに現れます。チャートのスパイクはキャッシュを壊してしまい、ユーザーが遅さを感じていることを示すサインになります。
本番環境でのAI支援キャッシュ拡張
「1ページ目+一般的なフィルターのみをキャッシュする」というルールを覚えていますか?このルールを少しだけ曲げてみましょう。上記のミス率75%を下げたいなら、1ページ目以外も対象にしてキャッシュを拡張する必要があります。ただし、拡張しすぎるとRedisインスタンスが肥大化するため、慎重に進める必要があります。
適切なキャッシュ拡張の判断を行うための、実践的なAI支援アプローチを以下に示します。
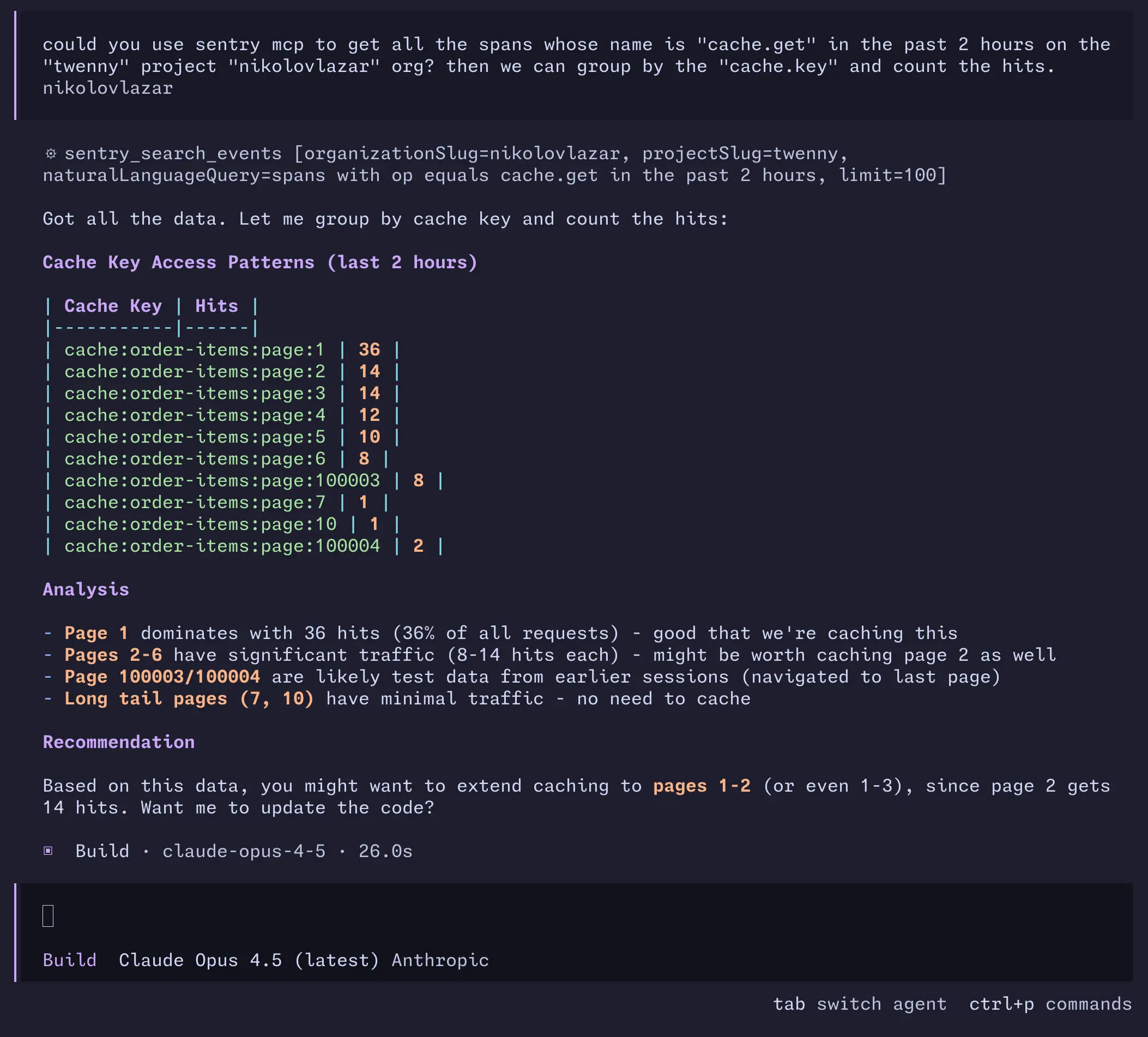
Sentry Model Context Protocol(MCP)を使うと、プロジェクト内の cache.get スパンをすべて取得し、cache.key プロパティでグルーピングできます。そのうえで、キャッシュをどのように拡張できるかをエージェントに提案してもらうことも可能です。
スクリーンショットを見ると、1ページ目が引き続き最もヒット数が多い一方で、2〜6ページ目にも一定のトラフィックがあることが分かります。7や10のような長尾ページはトラフィックが最小限なのでキャッシュする必要はなく、また破棄されたテストデータもいくつかあります。
エージェントは、キャッシュを3ページ目まで拡張することを提案しました。これがミス率にどう影響するかを見てみましょう。
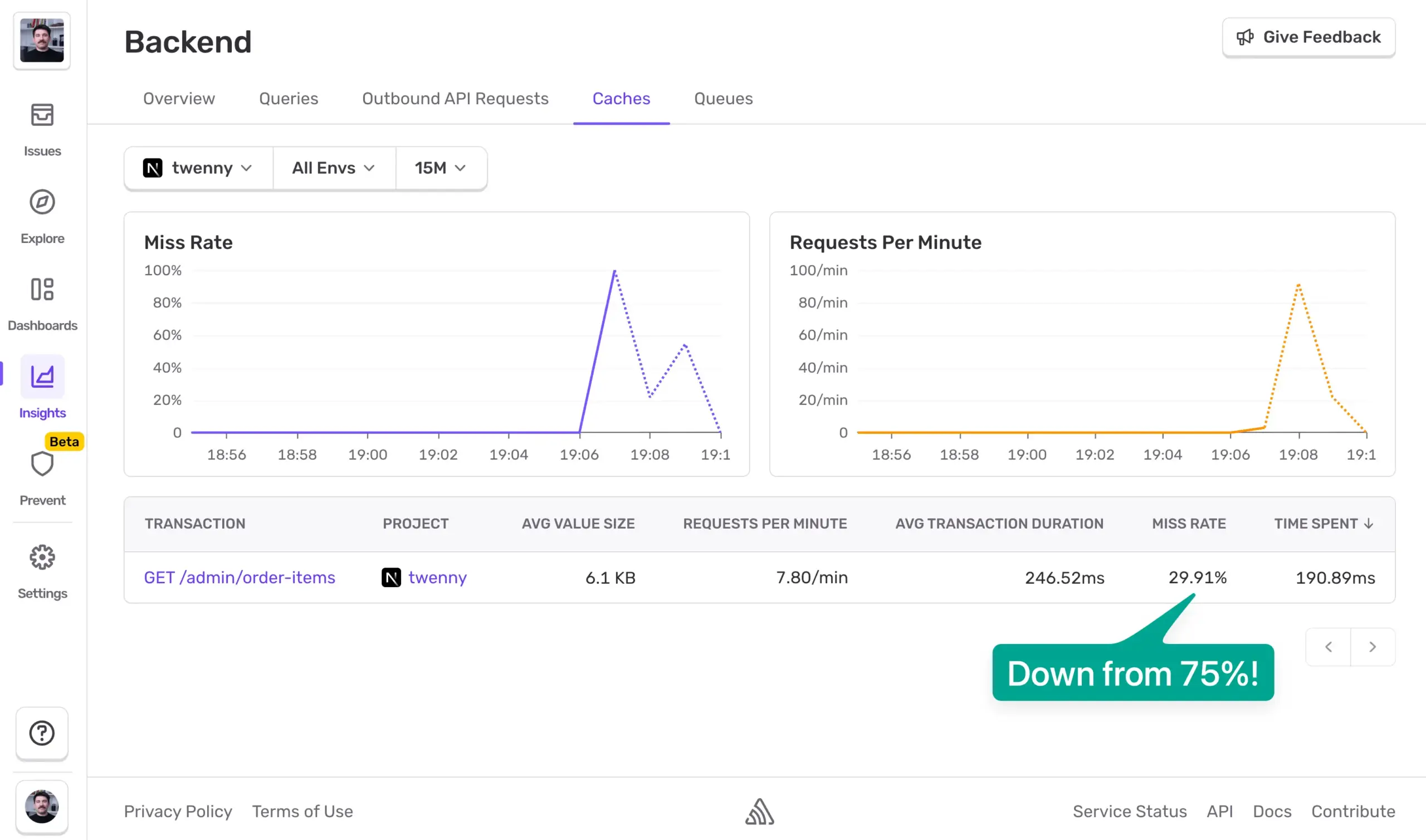
見てください!ミス率が75%から30%に下がりました。
つまり、データベースに到達するのはおおよそ3リクエストに1回だけ、ということです。ただし、Redisのメモリにも注意を払うことが重要です。キャッシュ対象を1ページ目から3ページ目まで押し広げると、Redisインスタンスが肥大化する可能性があり、その場合キャッシュは見合わなくなります。Redisの肥大化=ホットパスのエビクション(追い出し)であり、言い換えると、そもそもキャッシュで得られたパフォーマンス向上を打ち消してしまうということです。
ミス率の偏りに対するアラート設定
最後に行いたいのは、キャッシュミスに異常が発生したときに(メールやSlackで)通知するアラートを設定することです。
Sentry > Issues > Alerts に移動し、Performance Throughput を選択して、次のオプションでアラートを作成してください。
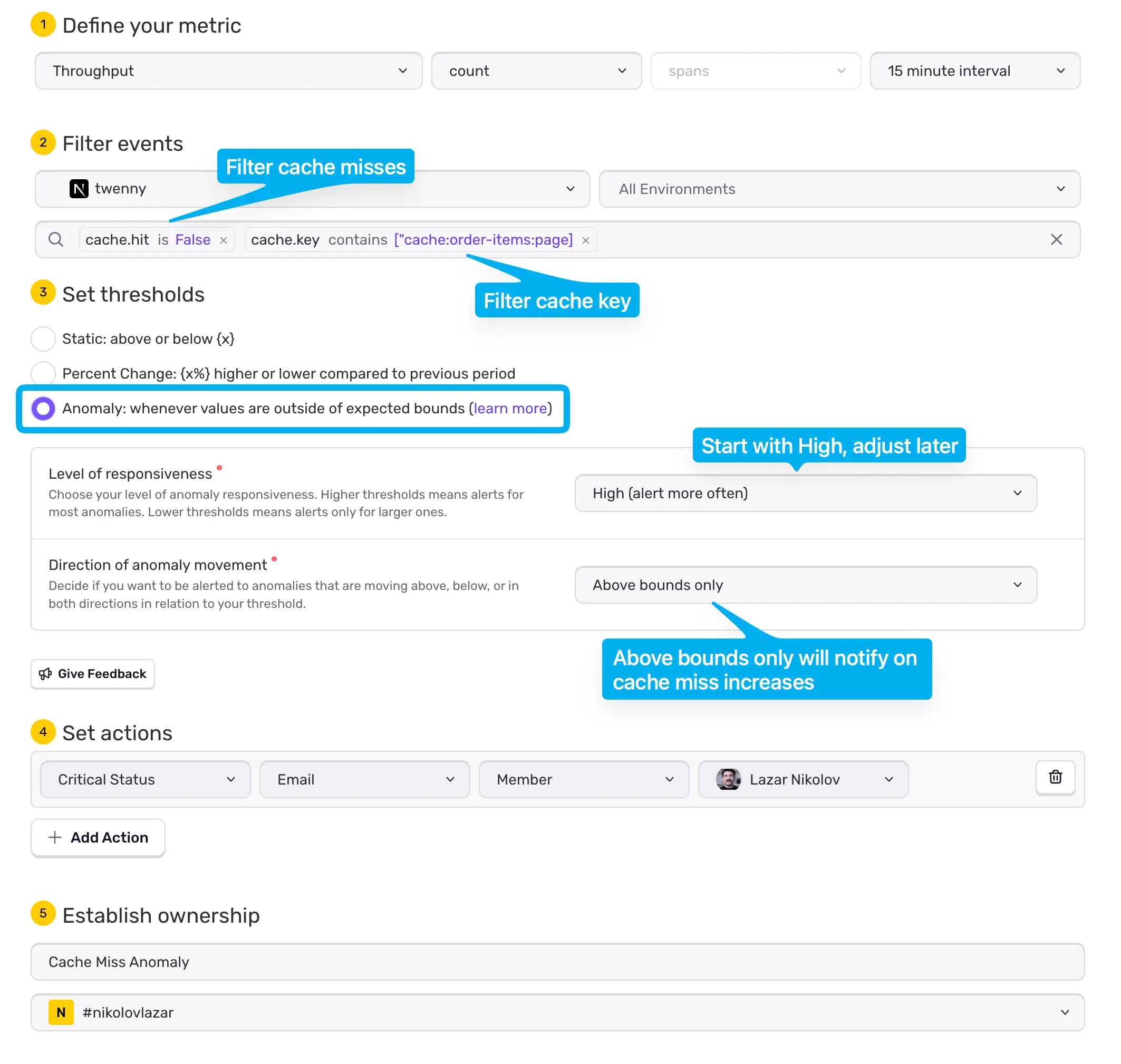
- プロジェクトと環境を正しく選択してください。
- cache.hit が False であること、そして cache.key でもフィルタリングするように設定します。
- しきい値(thresholds)は Anomaly に設定してください。
- 最初は responsiveness を High にして、あとで調整します。
- 異常の方向(Direction of anomaly movement)は Above bounds only にすると、キャッシュミスが増加した場合にのみ通知を受け取れます。
- 最後にアクションを定義してください。自分宛て/チーム宛てにメールを送るのか、特定のチャンネルに Slack メッセージを送るのかを選びます。
- 名前を付けて「Save Rule」をクリックします。
以上です。もし誤ってキャッシュの仕組みを壊してしまうと、キャッシュミスが大量に発生し、Sentry がそれを検知して通知します。フィルタは自由に設定でき、アラートはいくつでも作成できます。フィルタできる属性は cache.hit と cache.key だけではありません。フィルタバーをいろいろ試して、どんな条件で絞り込めるか確認してみてください。
ここから次に進むには
この時点でキャッシュは動作しています。エンドポイントは高速化され、データベースは保護され、通常動作を反映するベースラインのミス率も得られています。ここから先の作業は、キャッシュを追加することよりも、想定どおりに動き続けることを確認することに重心が移ります。
まず見るべきは、ミス率の絶対値ではなく「変動」です。安定していた線が急に跳ね上がる場合、多くは何かが変わったサインです。たとえば、キャッシュキーのバグ、新しいフィルタやソート、カーディナリティの増加、あるいはデプロイ時に入り込んだTTLや無効化のミスなどです。こうした変化は、ユーザーが不満を言い出す前にキャッシュメトリクスに現れがちです。
次に、ミス率は必ずレイテンシとセットで確認してください。P95/P99に影響しないミス率の増加は、通常は無害です。一方で、ミス率の増加によってDBスパンがクリティカルパスに戻ってしまうなら、それは対処すべき退行です。
キャッシュを拡張する際は、Redisのメモリとエビクションにも注意してください。より多くのページをキャッシュしてヒット率を改善できるのは、ホットキーがメモリ上に常駐している場合に限ります。頻繁なエビクションを引き起こすメモリ圧迫は、得られた成果を静かに打ち消し、キャッシュの挙動を予測しづらくします。
最後に、トラフィックの変化に合わせてキャッシュ境界を見直しましょう。利用パターンは変わります。先月は長尾だったページが、プロダクト変更や新しいワークフローによってホットになる可能性があります。キャッシュ戦略は、初期の前提に固定するのではなく、実際のトラフィックに合わせて進化させるべきです。
キャッシュメトリクスをガードレール(ベースラインのミス率、レイテンシとの相関、デプロイ後チェック)として扱えば、キャッシュは「触るのが怖い壊れやすい最適化」ではなく、システムの安定した一部になります。
Original Page: AI-driven caching strategies and instrumentation
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。

