
Article by: Sasha Blumenfeld
バグは丁寧に現れることはなく、チェックアウト機能をクラッシュさせ、認証を破壊し、APIの応答速度を極端に低下させます。しかも多くの場合、CEOから進捗状況を尋ねられる直前に発生します…。さらに、エラー通知ボックスが「TypeError: cannot read property of undefined」の亜種で埋め尽くされると、真に重要な問題を見極めることが困難になります。
そのため、デバッグにおける推測作業を排除するためのアップデートを展開しました。調査に費やす時間を短縮し、開発に集中できるようにすることが目的です。ユーザーに影響が及ぶ前にダウンタイムの通知を受け取り、サイト上で関連する問題やユーザーからのフィードバックを直接確認できます。また、AIによるアラートのグルーピング機能により重複を整理し、AI支援による修正により、問題の迅速な解決が可能になります。
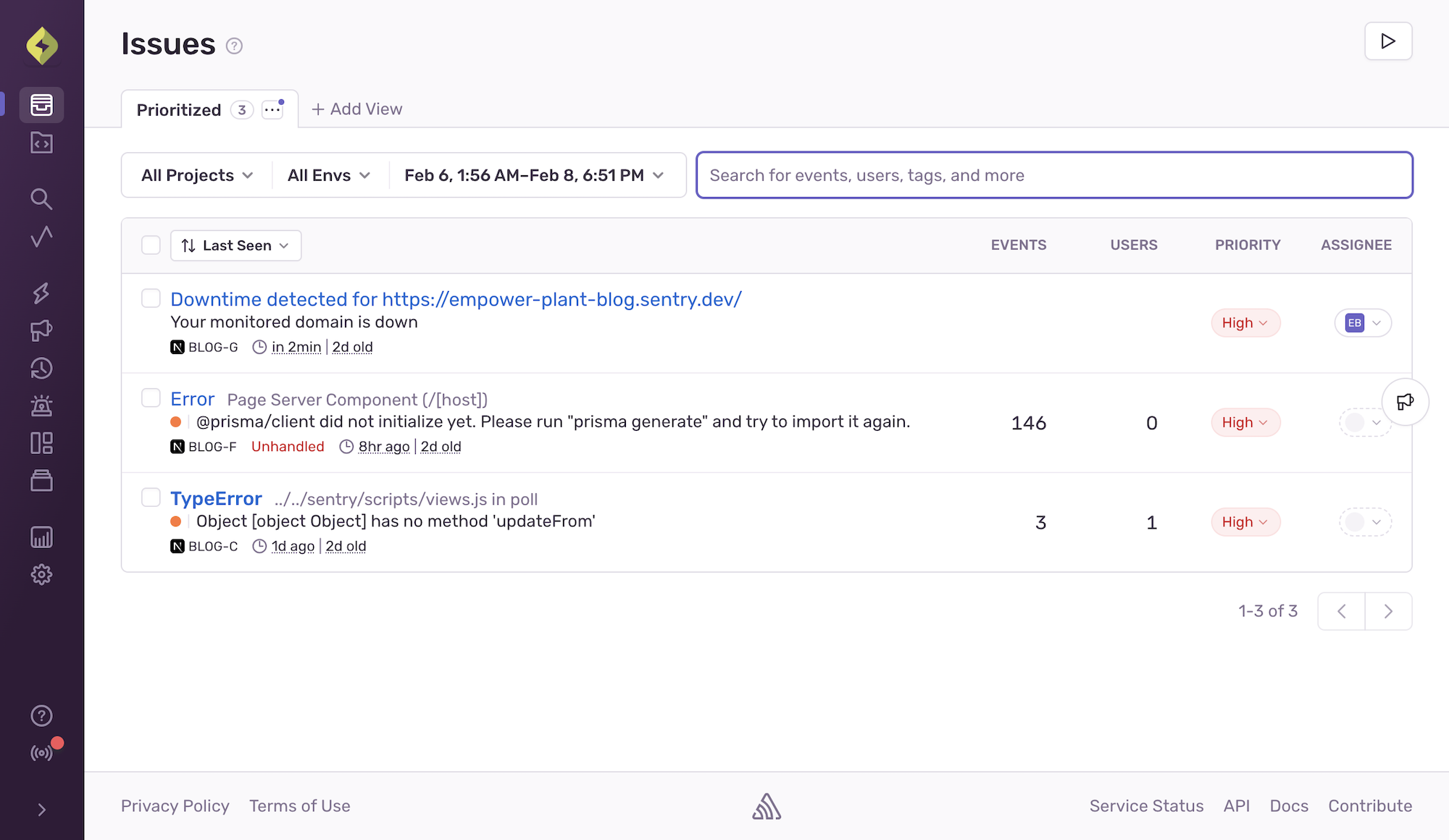
アプリ障害、上司より先に気づけていますか?
プロダクション障害はそれだけで問題ですが、それを CEO の Slack メッセージで知るのは最悪です。
現在一般提供中の Uptime Monitoring を使えば、SNS で炎上したり、全社ミーティングで取り上げられたりする前に、障害を検知することができます。
最短60秒間隔で実行されるグローバルチェックにより、障害発生の瞬間を即座に把握できます。
以下のことが可能です。
重要なフローの監視
たとえば、購入処理が突然止まったかどうかを検出するためのチェックアウトページやユーザーがログインできなくなっているかを確認するログインエンドポイントなどです。カスタム条件の設定
たとえば、ダウンタイムが60秒を超えた場合にのみ通知を受け取るように設定可能です。- 普段使用しているツールでの通知
Slack、PagerDuty、Teams、または Webhook 経由です。
たとえば、チェックアウトページが突然タイムアウトし始めたとしましょう。顧客からの苦情を待つ代わりに、即座にアラートが届きます。障害ログを確認すると、サードパーティの決済サービスの応答が遅いことが分かります。Sentry のエラーやトレースと照合することで、その遅延がどこで発生しているのか(APIの障害か、ネットワークの問題か、自分たちのコード内の何かか)を正確に特定でき、売上の損失が積み重なる前に修正できます。
私たちはこれまでに 40,000件のダウンタイムを検知しており、それらが大量のサポートチケットに発展する前に、チームが問題を特定できるよう支援してきました。
モニターは1つ無料でご利用頂けます。追加はモニター1つあたり月額1ドルです。HTTPメソッド、ヘッダー、ボディパラメータなど、リクエストの詳細を完全にコントロールし、特定のURLに対するカスタムアラートを作成できます。ぜひ試してください。詳細はブログでもご覧頂けます。
重複したエラーを掘り返すのはやめましょう
エラー受信箱が多数の通知で溢れていても、それが本当に10件の異なる問題なのでしょうか。それとも同じ問題の50通りのバリエーションでしょうか。現在受信しているアラートが、実は過去に対応済みのエラーの再通知である可能性もあります。
このように終わりのないアラートの中で混乱するのではなく、Issue Grouping を活用することで、関連するエラーを自動的にグループ化し、イズを削減できます。その結果、本当に修正すべき課題に集中することが可能になります。
例えばアプリケーションの複数箇所で API が、500 Internal Server Error を返している場合でも、Issue Grouping(AI Grouping)は、それらが単一の根本原因によるものなのか、複数の独立した問題なのかを判別します。また、ステージング環境と本番環境をまたいでエラーをグループ化できるため、同じ問題を重複して調査する無駄を防げます。
私たちはこのたび、Issue Grouping アルゴリズムに対し、過去最大規模の改善を実施しました。新たに導入された機械学習ベースの手法 により、新規 Issue の生成を約40%削減することに成功しました。この技術はカスタムのトランスフォーマー型テキスト埋め込みモデルを基盤としており、処理時間は100ミリ秒未満という高パフォーマンスを維持しています。これにより、より賢いIssue Groupingとアラートの削減を、作業スピードを損なうことなく実現できます。
再設計された Issue 詳細ページで、より迅速にトリアージ
アラートを受信した後は、次に何をすべきでしょうか。
新しい Issue 詳細ページでは、スタックトレース、ユーザーへの影響、パフォーマンスデータなどを個別に探し回る必要はありません。すべての情報が一元化されており、より迅速かつ効率的に問題の修正を行うことが可能です。
エラーが発生した際には、以下のことが可能となりました。
- 埋め込まれたトレース情報を確認
ビューを切り替えることなく、エラーやパフォーマンス問題を診断できます。 - より見やすくなったスタックトレース
根本原因の特定を迅速に行えます。 - ユーザーへの影響の概要を確認
実際の影響に基づいて修正の優先順位を判断できます。
たとえば、最近のデプロイで API レスポンスが遅延した場合、それがユーザーの1%に影響しているのか、30%に影響しているのかをすぐに確認できます。これにより、問題が些細な問題か、深刻な対応を要するものかを見極める重要な手がかりになります。そのままスタックトレース、タグ、修正に必要なコンテキストへとすぐにアクセスできます。
この新しい体験を試すには、Issue 詳細ページの右上にある「フラスコ」アイコンをクリックして有効にしてください。ご意見があれば、その同じメニューからフィードバックを直接お送りください。皆様の声を常に参考にしております。
エラーを迅速に理解し、さらに素早く修正しましょう
AttributeError: ‘NoneType’ object has no attribute ‘group’ というメッセージが表示されたとします。これどういう意味でしょうか?手作業でデバッグする代わりに、AI Issue Summaries がそのエラーと考えられる原因を簡潔に説明してくれるため、自分で情報をつなぎ合わせる必要がありません。

たとえば、バックエンドで KeyError: ‘user_id’ が発生した場合、要約には次のように説明されるかもしれません。
- これは辞書のキー参照時に該当するキーが存在しない場合に発生します。
- 原因としては予期しない APIレスポンスや欠損データが考えられます。
これは便利ですが、「何が問題か」を知っても、「どう直すか」がすぐにわかるとは限りません。
そこで登場するのが Autofix です。
How it works
たとえば、アプリが TypeError: cannot read property of undefined を投げたとします。ログを読み漁る代わりに、Sentry で Issue を開けば、Autofix が面倒な部分を自動で処理してくれます。
Autofix の機能は次のとおりです。
- コード内での問題発生箇所を正確に特定
- 欠損値を安全に扱う方法を提案
- そのまま適用できる修正案を提示
提案された修正内容は確認・調整が可能で、そのまま下書きのプルリクエストを作成することもできます。すべてSentry上で完結するため、ツールを行き来したり、複数の修正案を手作業でテストする必要はありません。
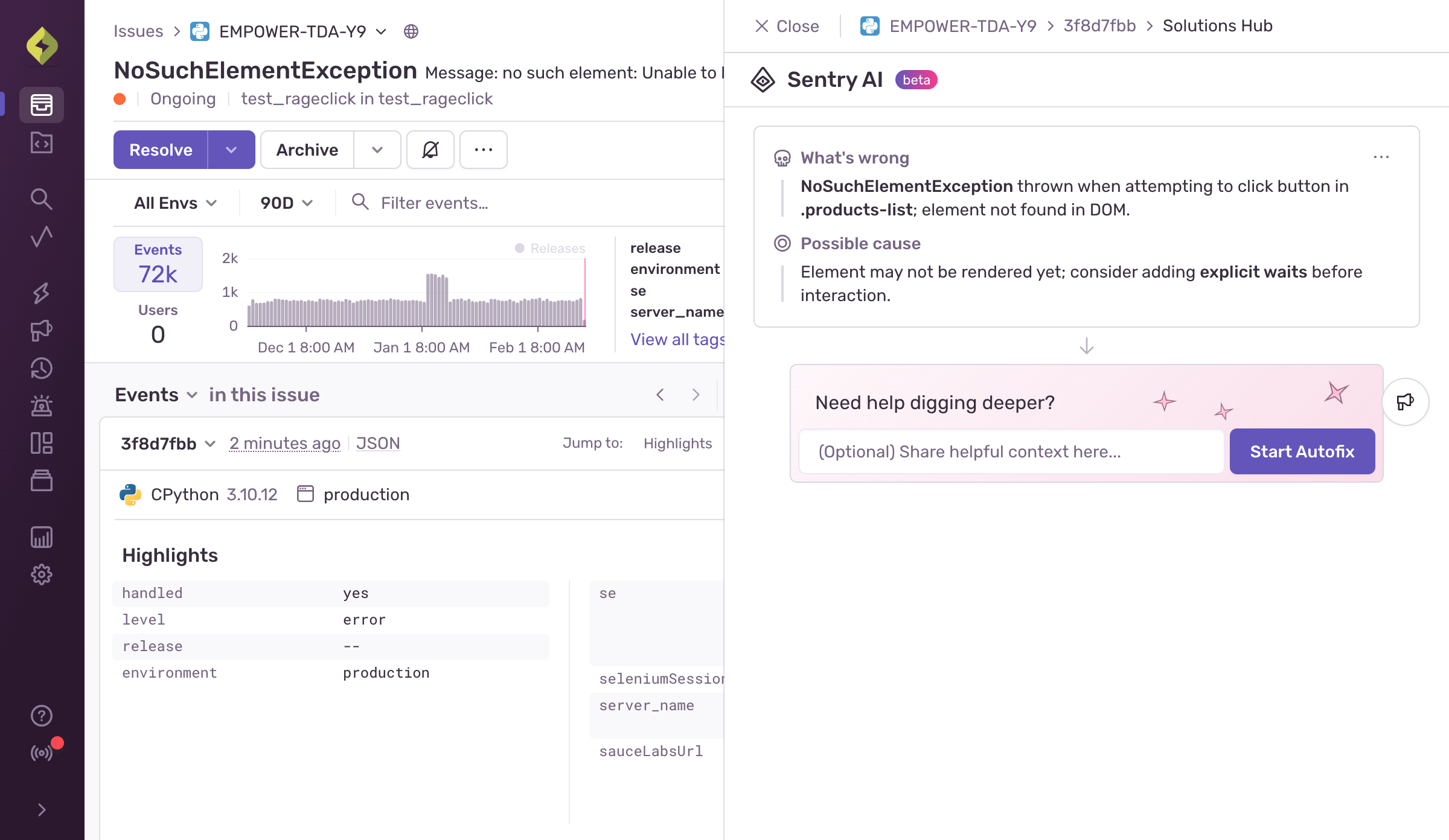
リリース以来、Autofix は 94.5% の確率で正しい根本原因を特定し、提案したコード変更によって 53.6% の確率で問題を修正することに成功しています。
Issue Summaryと Autofix は現在ベータ版であり、有料の Sentry ユーザーは無料で利用できます。利用を開始するには、Sentry AI を有効化してください。Issue 詳細ページの「Solutions Hub」からアクセスできます。Issues ページで任意のエラーをクリックするだけです。
ツールを切り替えることなく、あなたのサイト上からリアルタイムでデバッグ
フィーチャーフラグの背後に、新しいチェックアウトボタンをリリースしたばかりです。ユーザーからは「動かない」と報告がありましたが、私がテストすると問題は見当たりません。ログを掘り返して手動で再現を試みる代わりに、Dev Toolbar(ベータ版)を開けば、該当ページのライブエラー、フィーチャーフラグ、ユーザーフィードバックをその場で確認できます。

トラブルシューティングでは、次のようなことが可能です。
- フィーチャーフラグの確認
ユーザーに対して本当にボタンが有効化されていたのか、それとも古いバリアントに固定されていたのか? - ライブエラーの確認
JavaScriptの例外によってクリックが発火しなかったのでは? - ユーザーフィードバックの確認
同じ問題を複数のユーザーが報告しているのか、それとも単発のケースなのか?
Dev Toolbar はローカル環境・ステージング環境・本番環境のすべてで動作するため、問題を早期に検知して素早く解決できます。利用を開始するには、こちらのセットアップ手順をご確認ください。
新機能のロールアウトによる問題を追跡
新機能を公開した直後から、ユーザーからパフォーマンスの問題が報告され始めました。原因はその機能でしょうか。それともただの偶然でしょうか。
Sentry のFeature Flag 対応(ベータ版)を使えば、そのエラーが実験グループ・段階的ロールアウト中・予期しないフラグ状態のいずれで発生したのかをすばやく確認できます。
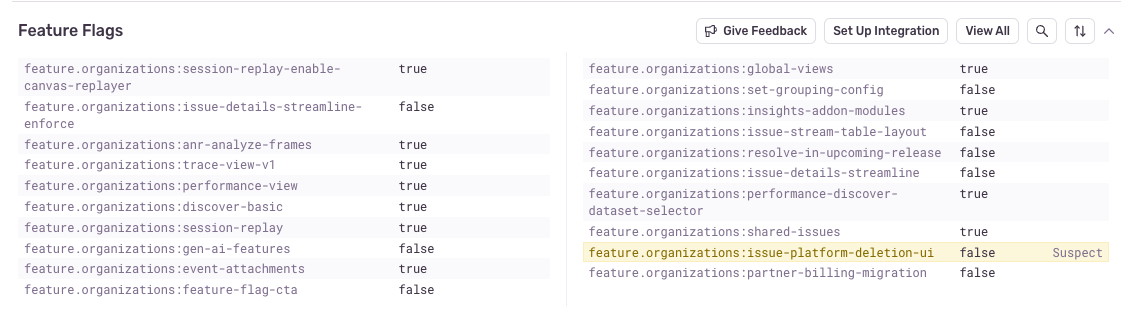
たとえば新しいチェックアウト機能をロールアウトしてエラーが発生し始めた場合、以下のことが可能です。
- エラー発生時に有効だったフィーチャーフラグの確認
- ロールアウト前後のエラー率の比較
- 問題を引き起こしている場合はフラグの即時無効化
最新のデプロイが原因かどうかを推測するのではなく、事実として把握できるようになります。評価と変更のトラッキングを始めるには、こちらのドキュメントをご覧ください。
より速くデバッグし、より賢く修正する
今回のアップデートにより、Sentry は問題が深刻化する前に検知し、その影響を的確に把握し、迅速に修正することを、これまで以上に容易にしました。他のツールが大量のデータを提示してユーザーを圧倒しがちな中、Sentry は問題の解決までの最短経路に重点を置いています。これにより、トラブル対応に費やす時間を最小限に抑え、開発やリリース業務により多くのリソースを割くことが可能になります。
Sentry のアカウントにアクセスして、これらの新機能を試してみてください。Discord での議論にもぜひご参加いただき、これらの機能の今後の方向性を共に形づくっていきましょう。
まだ Sentry アカウントをお持ちでない方もご安心ください。無料でお試し、またはデモをリクエストしてすぐに始められます。
Original Page: Breakpoint recap: Uptime Monitoring, robots, and feature flags galore
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。

