
Article by: Sergiy Dybskiy
本ブログの内容
- 「良い」LLM KPIとは?
- 抑えるべき LLM パフォーマンスの中核指標10選
- Sentry の AI オブザーバビリティを始める
- 他にも追跡しておくべき LLM メトリクス
- 次のステップ LLM を制御下に置くために
数か月前、トロントのオープンデータポータル向けに MCP サーバーを構築し、エージェントがユーザーの質問に関連するデータセットを取得できるようにしました。最初のバージョンを急いで作り、コードをざっと確認したところ、問題なさそうに見えたので、Claude に「トロント市における交通関連のデータソースにはどんなものがありますか?」と尋ねました。
ツール呼び出しは動作し、関連する結果も得られました。ところが、すぐにエラーが出ました。
「会話が長すぎます。新しい会話を開始してください。」質問を一度しただけだったのに。
原因は、最初の呼び出しで API から返された巨大な JSON ペイロードでした。それがコンテキストウィンドウを埋め尽くしてしまったのです。見ればすぐに解決できる簡単な問題でした。
しかし、モニタリングがない AI アプリには他にも様々な落とし穴があります。ツールのタイムアウトが黙って発生する、トークン使用量が急増する無限ループ、遅い検索、JSON フォーマットを壊すモデルのダウングレード、あるいは単純な500エラーなどです。
こうした場面があるからこそ、私は重要な問題をすぐに表面化させるために監視しているいくつかの主要な指標をまとめています。
「良い」LLM KPIとは?
Rahul が言うように、「プロンプトを入力してレスポンスが返ってくる。それはオブザーバビリティではありません。ただの“雰囲気”です。」
良いKPIとは生のカウンター値ではなく、プロダクトの成果に結びついた方向性のシグナルです。特にAIエージェントのパフォーマンス指標において重要です。
3つの視点で考えてみましょう。
- 信頼性:正しく動作しているか
- コスト効率:妥当な範囲でコストを抑えられているか
- ユーザー体験:速くてレスポンシブに感じられるか
以下のメトリクスはこれらの視点に直接対応しており、あなたも経験したことがあるであろう実際の障害とも結びついています。例えば、ループによるトークンスパイク、不安定なベクターデータベースがレスポンスを遅くする問題、あるいは静かに行われたモデル変更で出力品質が大幅に低下するケースなどです。
また、これらは「LLM 評価指標(LLM evaluation metrics)」「LLM メトリクス(LLM metrics)」「LLM レイテンシ(LLM latency)」といった一般的な検索用語とも一致しており、適切なガイダンスを探すのにも役立ち、あなたの情報を他の人が見つけやすくすることにもつながります。
抑えるべき LLM パフォーマンスの中核指標10選
エージェントトラフィック(一定時間あたりの実行回数)

内容と理由
トラフィック量はアプリの鼓動のようなものです。フラットライン(平坦化)は障害を示し、スパイク(急増)はループやフラッシュクラウド(瞬間的なアクセス集中)を意味するかもしれません。
ヒント
- 1分ごと、あるいは1時間ごとの実行回数をプロットする
- デプロイやフィーチャーフラグを重ねて表示する
- フラットラインや突然の10倍ジャンプにアラートを設定する
レンズ
信頼性、ユーザー体験(UX)
健全なパターンとは、予測可能な日次のリズムを描き、リリース後に緩やかな成長が見られる状態です。もしトラフィックが5分間フラットラインになったり、10分間ベースラインの3倍にスパイクしたり、閑散時間帯以外で50%以上低下した場合には調査が必要です。
LLM 生成数(モデルごとの呼び出し回数)

内容と理由
モデルの構成比を理解することが重要です。モデルのルーティングが変わると、コストやレイテンシ、失敗率が増加する可能性があります。
ヒント
- モデルやバージョンごとに分類する
- ボリュームの変化やルーティングの異常にアラートを設定する
レンズ
コスト、信頼性
通常はルーティング構成は安定しており、デプロイやフラグ変更のときだけ変化します。もし、あるモデルのシェアが7日間の中央値から20%以上変化したり、想定外のバージョンが出現した場合は調査が必要です。
ツール呼び出しと平均処理時間

内容と理由
検索API、ベクターデータベース、関数などのツールは、障害や遅延の一般的な原因となります。
ヒント
- ツールの呼び出し回数と処理時間を記録する
- スパイクやタイムアウトにアラートを設定する
レンズ:信頼性、ユーザー体験
成功率が高く、p95の処理時間が安定していることを目指しましょう。もしp95が50%以上伸びたり、タイムアウトが1〜2%を超えたり、新しいエラー分類が特定のツールでまとまって発生した場合は注意が必要です。
トークン使用量(プロンプト、補完、合計)

内容と理由
トークンはコストとレイテンシに直接影響します。スパイクはループやプロンプトの不具合を示していることが多いです。
ヒント
- リクエストあたりのトークン数をモデルごとに追跡する
- 外れ値や時間単位での急増にアラートを設定する
レンズ
コスト、UX
通常の挙動は、ルートやモデルごとにリクエストあたりのトークン数が安定しています。もし50%の急増、時間単位でのトークン急増、あるいは99パーセンタイル付近で、外れ値が増えている場合は調査が必要です。
LLMコスト(総支出)
内容と理由
コストはトラフィック、トークンの膨張、モデルの切り替えによって増加します。支出のスパイクは早期に検知しましょう。
ヒント
- モデルごとにコストを算出する
- 日次予算やリクエストあたりのコストが閾値を超えたらアラートを設定する
レンズ
コスト
健全な状態とは、リクエストあたりのコストが目標に沿い、日次合計が予算内に収まっていることです。もしコストがトラフィックよりも速く上昇したり、プロンプトやルーティング変更後にリクエストあたりのコストが増加した場合は対応が必要です。
エンドツーエンドレイテンシ(p50 / p95 + ファーストトークン)

内容と理由
レスポンス全体の時間も重要ですが、ユーザーが体感するのは最初のトークンが返るまでのレイテンシです。
ヒント
- p95、p99、ファーストトークンレイテンシを追跡する
- 週次のベースラインと比較して劣化があればアラートを設定する
レンズ
ユーザー体験(UX)
良いUXとは、ファーストトークンの時間が安定し、p95がSLO(サービスレベル目標)内に収まっている状態です。p95は最大でもp50の3〜4倍程度であるべきです。合計時間が横ばいなのにファーストトークンが遅くなったり、移動平均のベースラインに対してp95が20%以上悪化した場合は注意が必要です。
クリティカルステップの持続時間
内容と理由
生成処理をステージごとに分解しましょう 。例:検索、LLM呼び出し、ポストプロセス。これによりボトルネックを切り分けられます。
ヒント
- ステップごとにスパンや構造化ログを活用する
- ステージごとの最大処理時間にアラートを設定する
レンズ
信頼性、ユーザー体験(UX)
バランスの取れた実行では、どのステージも支配的にはなりません。あるステージが全体時間の60%を超えたり、7日間のベースラインに比べてp95が急上昇した場合は調査が必要です。
エラー数とエラー率

内容と理由
エラーには、ツール呼び出しの失敗、JSONパースエラー、モデルのタイムアウト、ルーティングミスなどが含まれます。
ヒント
- エラーの種類ごとに分類する
- エラー率が閾値(例:5%)を超えたらアラートを設定する
レンズ
信頼性
健全なシステムではエラー率は低く安定しており、パースエラーやタイムアウトも少数にとどまります。全体のエラーが5%を超えた場合や、特定の種類(JSONパース、タイムアウト、429など)でスパイクが発生した場合には対応が必要です。
エージェント呼び出し数とネスト深度
内容と理由
マルチエージェントのオーケストレーションはすぐに複雑化します。深いネストは無限ループの兆候であることが多いです。
ヒント
- リクエストごとの呼び出し深度を追跡する
- 深度が3を超えたり、異常なファンアウトがあればアラートを設定する
レンズ
コスト、信頼性
制御されたオーケストレーションでは、深度は1〜3の範囲に収まり、ファンアウトも制限されています。もし深度が3を超えたり、リクエストあたりの呼び出し数が急増したり、ユーザートラフィックに見合わないトークンの増加が見られた場合は調査が必要です。
ハンドオフ(エージェント→エージェント、または人間)
内容と理由
ハンドオフは、カバー範囲の不足やユーザーの摩擦を示します。ハンドオフ率の上昇は品質のレッドフラグです。
ヒント
- エスカレーションイベントをログに記録する
- ハンドオフ率の上昇にアラートを設定する
レンズ
ユーザー体験(UX)、信頼性
目標は、低いハンドオフ率を維持し、時間の経過とともに減少傾向にあることです。週ごとの増加や、特定のインテント、ルート、モデルに集中している場合は調査が必要です。
多くの最新の LLM オブザーバビリティツール(Sentry など)は、最小限の設定でこれらを可視化できます。以下に、Sentry で設定可能なダッシュボードやアラートの例を示します。
Sentry の AI オブザーバビリティを始める
以下は、Vercel AI SDK を使った最小限の Node.js の例です。
一度有効化すれば、Sentry のAI オブザーバビリティはモデル呼び出し、ツール実行、プロンプト、トークン、レイテンシ、エラーを自動的に捕捉します。そのうえで、重要な LLM メトリクスを中心にアラートやダッシュボードを構築できるようになります。
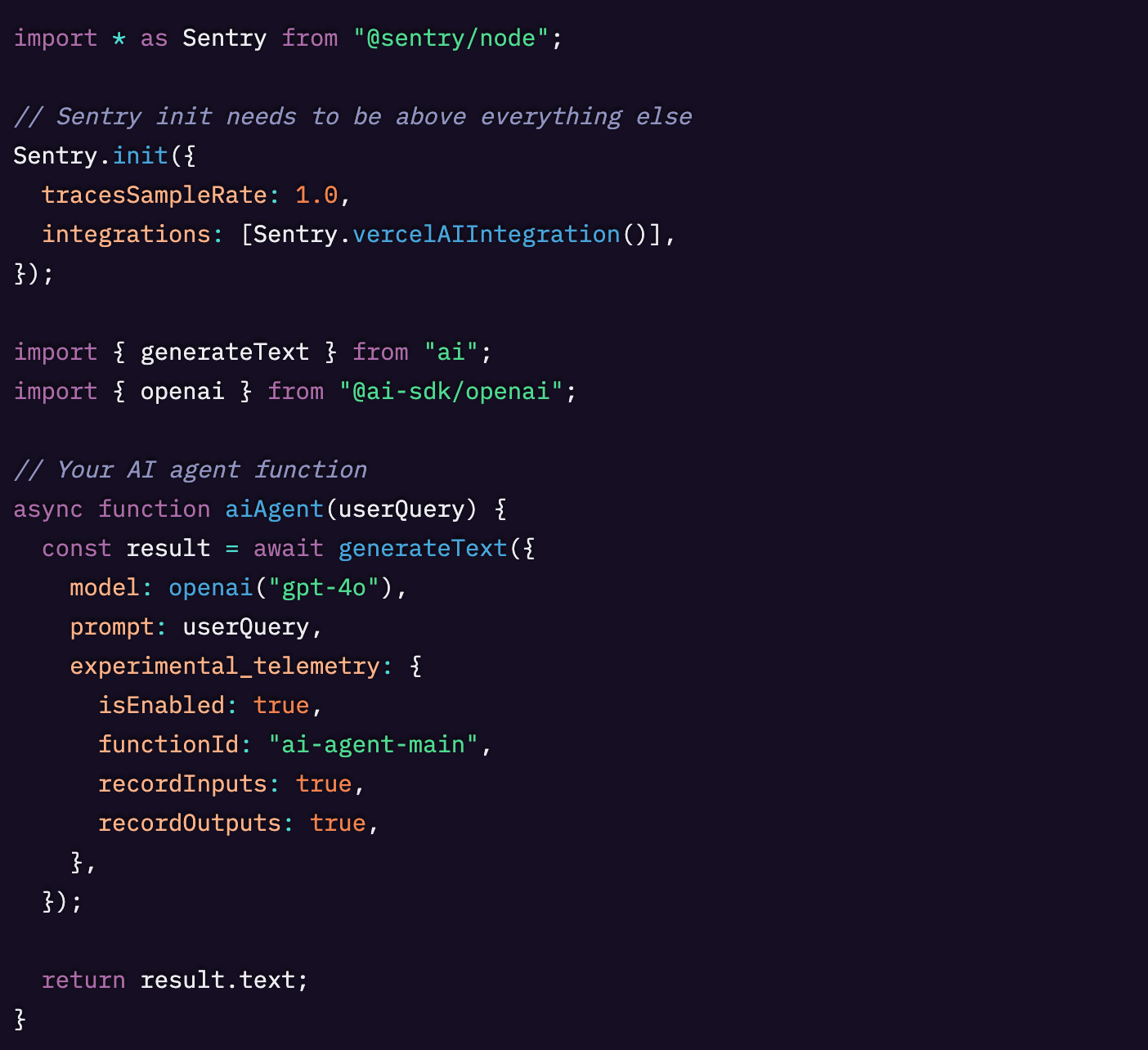
このセットアップでは、各エージェントの実行が完全なトレースにリンクされます。これにより、修正を確認するのが簡単になります。たとえば、遅かったスパンが改善されたかどうかを確認したり、p95レイテンシ、リクエストあたりのトークン数、エラー率に関するアラートでリグレッションを監視したりできます。
LLM 運用コックピット 初日に設定すべきダッシュボードとアラート


さまざまな AI エージェントや MCP モニタリングツールの詳細については、ドキュメントをご覧ください。
私たちが提供するデフォルトビューに加えて、信頼性・コスト効率・ユーザー体験を監視するために役立つ、カスタムダッシュボードやアラートの設定例を以下に紹介します。
モデルごとの日次コスト
異なるモデルごとのコストを、プロバイダーのダッシュボードをいちいち見に行くのではなく、1つのウィジェットで把握できるようにすると、運用がシンプルになります。さらに、月末に請求書を待つのではなく、高額支出に対してアラートを設定しておくと安心です。
エンドツーエンドレイテンシ
コストだけでなく、それぞれのモデルがどのように動作しているかを理解することも非常に重要です。ユーザー体験を把握するうえで役立つ3つのデータポイントは次のとおりです。
- AIレスポンスの最初のチャンクまでの平均時間(ミリ秒):LLM から最初のペイロードを受け取るまでにかかった時間
- AIレスポンス完了までのp50時間(ミリ秒):LLM レスポンス全体が完了するまでの、一般的なユーザー体験
- AIレスポンス完了までのp95時間(ミリ秒):調査が必要な異常値を把握するのに役立つ指標
即効性のあるクイックウィン
- デプロイやフラグを重ねて表示し、KPI のスパイクと変更点を対応づけることで、根本原因分析を迅速化する。
- トークン数、コスト、p95レイテンシ、エラー率のアラートから始めることで、ノイズを最小限に抑えつつ高コストなリグレッションを捕捉する。
- プロンプトや出力ではなく、運用テレメトリを保持することで、プライバシー要件を満たしつつ、アラートに必要なメトリクスを失わないようにする。
他にも追跡しておくべき LLM メトリクス
- 幻覚(ハルシネーション)率と事実正確性率
- 有害性やバイアスのスコア
- RAG における検索精度と再現率(precision / recall)
- ユーザーの感情(賛成/反対のフィードバックや CSAT)
- ハードウェア利用率(CPU・GPU)
- プロンプト品質とバージョン管理
- ポリシー違反のカウント
次のステップ LLM を制御下に置くために
大量のチャートは必要ありません。必要なのは、AIエージェントにとって正しいパフォーマンス指標です。すなわち、トラフィック、トークン、コスト、レイテンシ(ファーストトークンレイテンシを含む)、エラー、そしていくつかのオーケストレーション指標です。現在のオブザーバビリティ環境をこれらの LLM 評価指標に照らして監査し、不足を補い、適切なアラートをいくつか設定しましょう。
すでに Sentry でエラーやトレースを利用している場合は、AIエージェントモニタリングを有効化し、自分のアプリ内でこれらのダッシュボードを確認できます。また、AIオブザーバビリティに関するドキュメントもぜひご覧ください。
Original Page: The core KPIs of LLM performance (and how to track them)
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。

