Article by: Kyle Tryon
本ブログの内容
- レイテンシの特定
- なぜエッジコンピューティングが重要なのか
- エッジで計算するには?
- TL;DR
Google の研究者たちが 2017 年に行った調査によると、次のような結果が得られました。
ページの読み込み時間が 1 秒から 3 秒になると、ユーザーが離脱する確率は 32% 増加する。
これは8年以上も前の話です。そして正直なところ、それからユーザーの忍耐力が増したとは考えにくいでしょう。
Web Vitals とは、Google が定義した一連のパフォーマンス指標で、ユーザー体験を測定するためのものです。たとえば次のような要素に着目しています。
- LCP(Largest Contentful Paint):主要コンテンツが読み込まれるまでの時間
- INP(Interaction to Next Paint):ページが入力に反応するまでの速さ
- CLS(Cumulative Layout Shift):アプリの視覚的な安定性(=コンテンツが予期せずずれ動くかどうか)
わずか 1 秒の遅延でさえ売上の減少や登録機会の損失につながる可能性があるため、あらゆる観点からレイテンシ(遅延)を調査することが重要です。
どれだけ最適化されたアプリケーションであっても、プルリクエスト(PR)だけでは解決できないボトルネックが少なくとも1つは存在します。それが「距離(distance)」です。
レイテンシの特定
見えないものは、直すことができません。
たとえば、あなたのサービスがアメリカ国内の単一サーバー上で稼働している場合、アジアやヨーロッパといったより遠方にいるユーザーは、単純にリクエストの移動距離が長くなるため、読み込み速度が遅くなるのは自然なことです。
ここでは、Sentry を使って地域ごとのレイテンシの影響を測定・可視化するための基本的なセットアップ手順を紹介します。
テスト環境の構築
今回は、フロントエンドアプリとバックエンド API を含む EC サイトを、米国の iad(バージニア州アッシュバーン)リージョンにデプロイします。使用するのは Fly.io で、最大35のリージョンに簡単にコードをデプロイできます。
フロントエンドとバックエンドは、同じリージョン内に2つの別々のVM(仮想マシン)としてデプロイされます。現時点では、すべてのトラフィックは米国内からのアクセスのみです。
これが、私たちの「理想的な」ベースライン環境になります。
Sentry を使ってレイテンシを可視化
Sentry のダッシュボードから、Explore > Traces をクリックして、アプリケーション内のすべてのトラフィックを確認します。各 スパンは、アプリ内で測定可能なイベントやアクションを表します。
左上のドロップダウンメニューから、トレースを確認したいプロジェクトを選択できます。ここでは、ユーザー体験を測定できるフロントエンドアプリケーションに注目します。
次に、「Visualize」の設定を「count」から「span.duration の平均(avg)」に変更します。これにより、スパンの生データ数だけでなく、各スパンが平均してどのくらいの時間を要しているのかを分析できるようになります。
さらにその下にある 「Group By」 のドロップダウンから user.geo.country_code(ユーザーの国コード) を選択すると、国別の平均処理時間を確認することができます。

今回のデモでは、私たちだけがアクセスしているため、アメリカの単一のデータグループしか表示されていません。アプリが複数の国からトラフィックを受け取っている場合は、ここにそれらすべてが表示されます。
ただし、現在はすべてのスパンの平均時間が表示されています。代わりに、測定したい特定のイベントに検索範囲を絞ってみましょう。
コード内の任意のコールバックを Sentry.startSpan で手動でラップすることで、検索しやすい特定のプロパティを与えることができます。
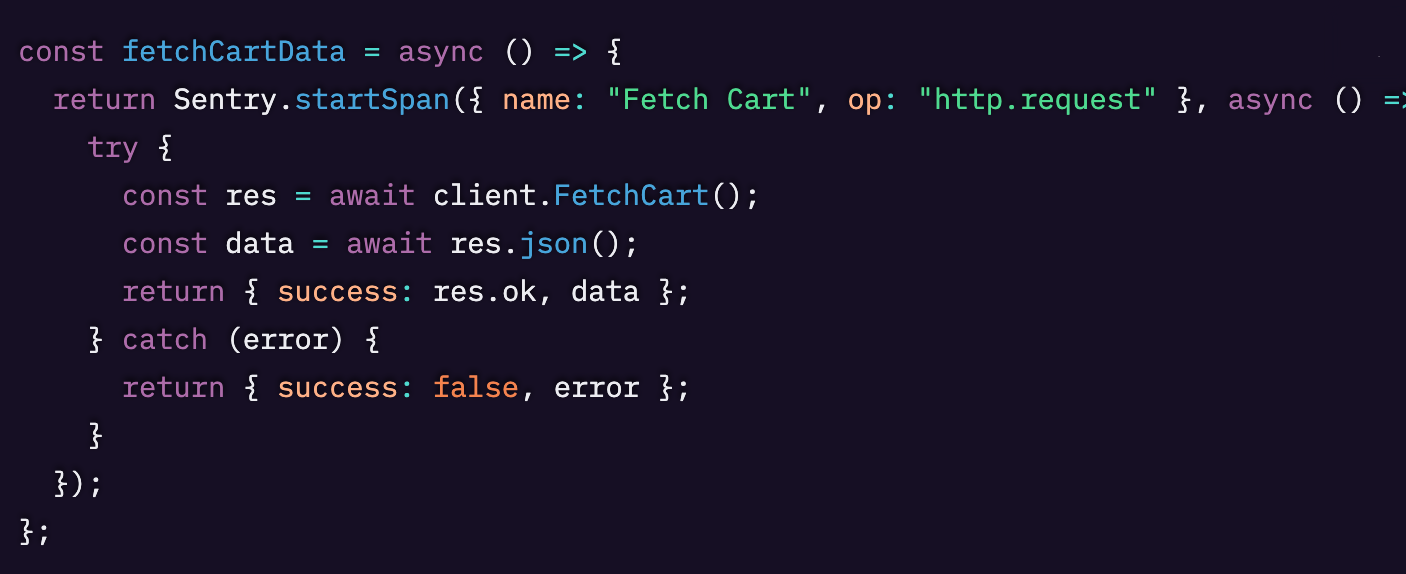
この場合、カートの中身を読み込む処理を担う呼び出し部分をアプリケーション内でラップしました。名前を設定することで、span.description を使ってこのスパンを簡単に検索できるようになります。

以前は、スパンの平均処理時間が 8.14 秒 でしたが、「Fetch Cart」スパンのみに絞り込んだところ、新たな平均は 7.84 秒 になりました。
このデモでは、サーバーに意図的に高負荷をかけているため、動作はかなり遅くなっています。しかし、サーバーのバックエンドがユーザーから物理的に離れた場所、たとえば日本にデプロイされていた場合と比べてどうなるか見てみましょう。
なぜエッジコンピューティングが重要なのか
従来のアプリケーションは(特にデータベースの場合)しばしば単一のリージョンに固定されているため、最適化によって改善できる範囲に比べて、レイテンシが大きなボトルネックになり得ます。
ではもう一度テストを実行してみましょう。今回はバックエンドを日本(nrt)にデプロイします。これは、日本に拠点を置くサービスが、アメリカにユーザーを持つ場合に相当します。
コードはまったく同じです。ばらつきは多少あるでしょうが、ここから見られる追加の処理時間は、平均して一時的なレイテンシによるものと考えられます。

「Fetch Cart」イベントの新たな平均スパン時間は 17.2 秒 となり、以前の2倍以上になりました。
この差の一部は、呼び出しの性質によるばらつきに起因するかもしれませんが、大部分は、フロントエンドサーバーが物理的に遠く離れたバックエンドと通信する際の移動時間によるものです。
実際のアプリケーションでは、今回と同様に サーバーが単一のリージョンにデプロイされているかもしれません。その場合、同じグラフ上に 複数の国からのトラフィックが表示されることになりますが、問題の本質は同じです。
エッジで計算するには?
エッジコンピューティングとは、サービスやデータをユーザーの近く(物理的に)にホスティングするという考え方です。
エッジコンピューティングプロバイダーは、通常、ユーザーを自動的に最も近い場所にルーティングします。
現代的なソフトウェアのパラダイムの中には、グローバルに「クラウド」でシンプルな関数を実行できるものもあります。エッジネットワーキングは、Vercel の「Vercel Functions」や Cloudflare の「Workers」 のようなサーバーレスプロバイダーでよく利用可能です。
Sentry を使って リージョンごとの平均トレース時間を測定することで、バックエンド(およびある程度はフロントエンド)から離れるほど、ユーザー体験が悪化していることがわかります。では、ユーザーにとって最速の読み込み時間を保証するにはどうすればよいのでしょうか?
エッジコンピューティングや CDN(ユーザーの近くにファイルを保存する仕組み)に対応したソリューションを提供するホスティングプロバイダーやクラウドプラットフォームは、多数存在します。
サーバーレス関数
サーバーレスのエッジ関数は、インフラを管理することなく、コードをユーザーの近くに移動させる最も簡単な方法のひとつです。AWS Lambda@Edge、Cloudflare Workers、Vercel Functions といったプラットフォームでは、軽量でステートレスな関数を世界中のデータセンターで実行できます。
これらのプラットフォームは、スケーリング、プロビジョニング、ルーティングを自動で処理してくれるため、開発者はコードを書くことに集中でき、ユーザーに最も近い場所から即座に実行されることが期待できます。
Next.js のような人気のモダンフレームワークの多くは、サーバーレスエッジプラットフォームでの関数実行をサポートするアダプターや組み込み機能を備えています。人気のあるフレームワークを使用していれば、エッジへの移行はプラグイン1つで済むかもしれません。
コンテナ
アプリを小さなステートレス関数に分割できない場合、エッジで実行する次の選択肢はコンテナです。Docker 上で動作するほぼすべてのものは、エッジリージョンの VM にデプロイ可能です。
Fly.io のようなプラットフォームは、数十のリージョンにマイクロVM をデプロイすることを専門としており、ほぼすべてのアプリに対してサーバーレスのような機能を提供します。
コンテナを使えば、フルスタックサービス、カスタムランタイム、バックグラウンドプロセスなどを複数の場所で実行可能です。たとえば、フロントエンドと API を複数のエッジリージョンにデプロイし、自前で高可用性の Postgres クラスターを管理するといった構成も考えられます。
ここでのメリットは柔軟性にあり、必要なものを、必要なリージョンで正確に実行できるという点にあります。一方で、その代償として、スケーリング、ヘルスチェック、フェイルオーバー、イメージの最新化など、運用面の責任が増大します。しかし、サーバーレスの制約に収まりきらない複雑なアプリケーションにとって、コンテナはアーキテクチャを書き換えることなくグローバル展開を可能にする強力な手段となります。
データベース
アプリをエッジに展開しようとする際、最も対応が難しいのがデータベースです。フロントエンドやバックエンドは比較的簡単にユーザーの近くへ移動できますが、データも一緒に移動させる必要があり、そこが複雑になります。
一般的な構成(たとえば Supabase 上の Postgres)では、リードレプリカは、別のリージョンで動作するプライマリデータベースの完全なコピーです。これはプライマリからの変更をストリーミングで受け取り最新の状態が保たれ、ユーザーに物理的に近い場所にあるため、クエリの応答が高速になります。
書き込みは依然としてプライマリに送られますが、読み取りは最寄りのレプリカで処理され、ラウンドトリップ時間が短縮され、プライマリの負荷も軽減されます。その代償として、各レプリカに対してコンピュートとストレージのコストがかかり、わずかなレプリケーション遅延も発生します。
Neon はこれとは異なるアプローチを採用しており、「サーバーレス」な Postgres を提供しています。Neon では コンピュートとストレージが分離されているため、レプリカを立ち上げる際にすべてのデータをコピーする必要はありません。
代わりに、同じストレージ層を指す別のコンピュートノードが作成される仕組みです。

Neon リードレプリカ:Neon ドキュメント
これにより、使用していないときにコンピュートをゼロまでスケールダウンし、必要に応じて他のリージョンでレプリカのコンピュートノードをすばやくスピンアップすることが、安価かつ高速に行えます。一方で潜在的な欠点として、同じストレージ層から読み取るため、コストは節約できる一方で、追加のレイテンシが発生する可能性もあります。
それが フルの Postgres リードレプリカであれ、サーバーレスな Neon のコンピュートノードであれ、目的は同じです。ユーザーの近くに処理を移動し、クエリの応答を速くすること。
KV のようなキャッシュと組み合わせることで、グローバルに分散されたアプリを高速に感じさせる最も効果的な方法のひとつとなります。
TL;DR
レイテンシが上がると、ユーザー体験は悪化します。わずか 1 秒の遅延でも、売上や登録の機会を失う可能性があります。
Sentry を使えば、地域ごとのユーザー体験における実際のパフォーマンスを測定し、物理的な距離が読み込み時間にどう影響するかを正確に把握することができます。サーバーレスコンピュート、リードレプリカ、コンテナによるデプロイなど、最新のエッジコンピューティングのパラダイムを活用することで、アプリケーションをユーザーの近くに配置し、ラウンドトリップ時間を短縮し、どの地域のユーザーにも高速な体験を提供できます。これらを スマートなキャッシュ戦略と組み合わせれば、グローバルなユーザーに対してスムーズで信頼性の高い体験を届けることが可能になります。
Original Page: How to measure and fix latency with edge deployments and Sentry
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。

