Article by: Will McMullen
チェックアウトフローが壊れると、顧客は「最先端」のJSメタフレームワークが廃れるよりも早く離れていきます。幸い、Sentry を使えば、顧客のチェックアウトのようなクリティカルパスにオブザーバビリティを設定するのは簡単です。ここでは、私たちがどのようにインスツルメントし、監視し、大きな問題を最小限の労力で修正したのかを順を追って紹介します。
チェックアウトフローのインスツルメント
まず、ユーザーがチェックアウトプロセスとどのようにやり取りしているかを正確に追跡したいと考えました。Sentry の Distributed Tracing を使って監視ダッシュボードを設定するのは簡単でした。フロントエンドとバックエンドのアプリケーション(今回の場合は app.py と App.tsx のトップレベルファイル)でトレーシングを有効化し、/api/ エンドポイントを tracePropagationTargets に追加して Distributed Tracing をセットアップするだけで完了です。
これで、Flask と React の両方にわたって、パフォーマンスメトリクス、エラー、トレーシングデータを取得できるようになりました。
ユーザージャーニーの監視
Sentry にデータが集まるようになると、eコマースストアフロントで最も重要な要素であるチェックアウトフローを監視するためのダッシュボードを立ち上げるのは非常に簡単でした。

ここに到達するために、私たちはいくつかの主要な属性で Span データ を拡張しました。これらは Sentry で Span Metrics として可視化・監視できます。誰かが Cart.jsx コンポーネントを使うたびに、Sentry SDK でのインスツルメンテーションによって「カートに追加されたアイテム数」をそのアクティブな Span に付与し、その数を追跡できるようにしました。
実際のところ、次のような形になります。
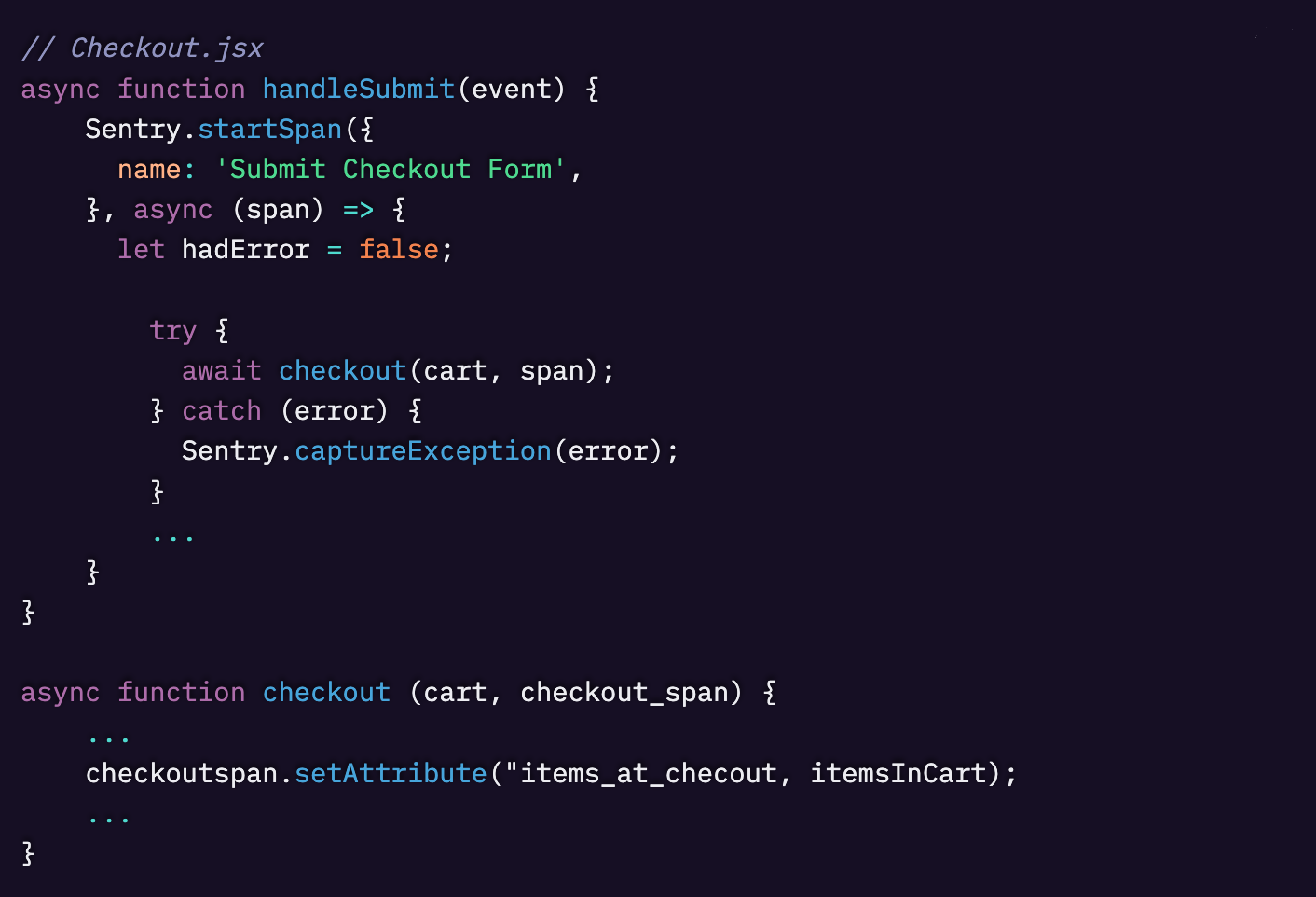
まず、Sentry.startSpan() でスパンを作成し、次に checkoutspan.setAttribute を使って items_at_checkout を属性として追加します。ここにデバッグやパターン分析のために顧客データなど他の有用な情報を付与することも簡単にできますが、ここではシンプルに留めることにしました。
問題の発見
この仕組みがどれほど役立つか、すでにイメージできるかもしれません。APM や信頼性データをひとつの画面で、ユーザーの基本的な分析データを別の画面で確認するのではなく、ユーザーにとって最も重要なジャーニーの中でキーとなるシグナルを、デバッグを始めるその場で監視できるのです。これにより、単なる稼働時間やエラー急増といった次元では捉えられない「障害」を発見する能力が劇的に向上します。
今回のケースでは、人々がカートに追加するアイテム数が完全にゼロになってしまったのを確認しました。通常であれば、こうしたデータはプロダクト分析ツールに存在し、あるチームがそれを監視し、即座に Sev1 インシデントとしてエスカレーションし、大勢のメンバーを招集する必要がありました。
しかし今回は、同じタイミングで /products および GET products エンドポイントでエラーが急増していることを即座に確認できたため、エラーを掘り下げてみると、2つの問題がありました。
- Flask(バックエンド): TypeError: Argument of type ‘NoneType’ is not iterable
- React(フロントエンド): TypeError: Failed to Fetch
繰り返しになりますが、Sentry のおかげで、ユーザー体験に最も影響を与える部分でフルスタックの問題が発生していたことを即座に把握することができました。
Distributed Tracing でフロントエンドの背後を追う
ここからが本当の見せ場でした。React 側の問題だけではデバッグに十分な情報がありませんでした。ところが「View Full Trace」をクリックすると、その背後にある Flask バックエンドのエラーがはっきりと浮かび上がったのです

私たちのバックエンドの http.server リクエストで、上流の問題が発生していました!そのイシューをクリックすると、根本原因がはっきりと確認できました。

ありがちな“vibe coding”のうっかりミスです。product_inventory を空の配列にする代わりに None で初期化していたため、反復処理が不可能になっていたのです。
修正
修正は、在庫を正しく初期化するために簡単な調整を加えるだけでした:product_inventory = []。これにより、型エラーを投げる代わりにフロントエンドへ空の配列が渡されるようになり、空の検索結果を正しく処理できるようになりました。私たちは、バックエンドのコードベースを自力で grep したり、別のオンコールシフトに入っているチームメイトを呼び出したりすることなく、問題の特定からトリアージ、解決までをほんの数分で終えることができました。
しかし、これでも私の感覚ではまだ「受け身すぎる」ものでした。ダッシュボードを監視し続ける代わりに、スパンメトリクスにアラートを設定し、適切なチームにルーティングすべきです。やるべきことは、Trace Explorer で Cart Value ウィジェット のクエリを開き、クエリを微調整してアラートを作成するだけです。
パフォーマンス監視は開発者(&SRE)に嫌われない
クリティカルなユーザー体験をインスツルメントし、カスタマージャーニーを監視し、問題を特定し、スタック全体をデバッグするのは、苦痛である必要はありません。わずか数行のコードで、Sentry はコンテキスト切り替えの混乱なしに明確さを提供します。
Sentry で Distributed Tracing とアプリケーションオブザーバビリティを始めるには、フロントエンドとバックエンドの両方で Sentry.init() を通じてコードに組み込み、ブラウザトレーシング統合を有効にするだけです。準備はそれで完了です。React とPython でぜひ試してみてください。
プロジェクトで Distributed Tracing を試して、顧客(そしてあなたの正気)を守りましょう。高スループットのアプリを持っているなら、Settings → Billing からトレーシングトライアルを開始してください。初めての方は、今日から Sentry の無料トライアルを始めてみましょう!
質問やフィードバック、問題があれば、Discord でぜひご連絡ください。
Original Page : Monitoring & Debugging a Checkout Flow in Flask & React
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。

