Article by: Kyle Tryon
要約:一律のサンプリングレートは無駄や非効率につながることがあります。独自のサンプリングロジックを用いて、ノイズを減らしつつ100%のシグナルをキャプチャし、アプリケーションの監視方法を細かく調整しましょう。
高トラフィックの本番環境では、テレメトリはユーザー体験への最も直接的なリンクです。Sentry に送られるすべての Span、Trace、Log、Replay は、本番環境で実際に何が起きているのかを高い精度で可視化してくれます。
しかしその可視性から最大限の価値を引き出すには、シグナルとノイズをどう切り分けるかを理解しておく必要があります。安定したレガシールートにおける通常の「ページ読み込み」を、チェックアウトフローや新機能リリースのような重要な体験と同じ強度で扱っていては、収集するデータを最適化できているとは言えません。
スケールしても持ちこたえ、クォータも圧迫しないオブザーバビリティ戦略を構築するには「一律サンプリング」を超えていく必要があります。重要な箇所や変化の速い箇所では高解像度のデータを優先し、安定しているシステムでは設定を最適化する必要があります。
すべてを100%サンプリングすればいいのでは?
可能です!
アプリが小規模だったり、まだ新しかったりするなら、それが実際に正しい方針である場合もあります。しかしスケールしていくにつれ、「すべてを100%」はたいてい現実的な選択肢ではなくなります。
理由はいくつかあります。
- シグナル対ノイズ(Signal-to-Noise): テレメトリデータはひと目で何が起きたかわかるときに、より役立ちます。チェックアウト中にユーザーが問題を経験した100件を見つけるために、100万件の「ユーザーがボタンをクリックした」span を解析しなければならないのは、あなたにとっても、クエリにとっても、そして私たちと同じ情報を利用する可能性のあるLLMにとっても、効率的ではありません。
- ネットワーク負荷(The Network Footprint): SDKは高度に最適化されていますが、あらゆる操作、あらゆる関数呼び出しは、積み重なると負荷になります。必要なものだけをサンプリングすることで、価値ある情報を収集しながら、高いパフォーマンスを維持できます。
基本の調整項目:静的サンプルレート
Sentry を初期化する際には、送信するデータ量を調整するための主要なオプションが4つあります。まず最初のステップはそれぞれがどう連動するのかを理解することです。
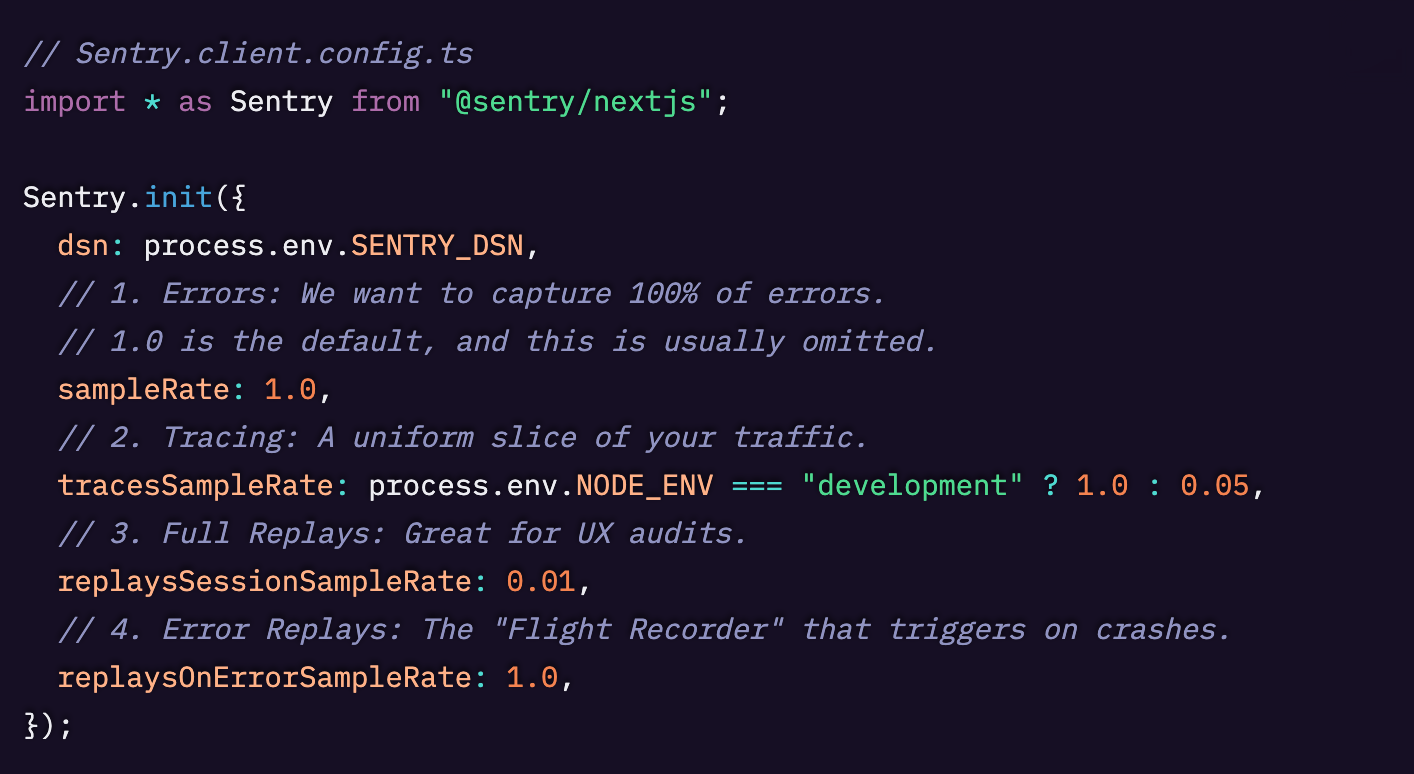
- sampleRate:エラー向けです。何かが壊れたら、毎回必ず把握したいので、私たちはほぼ常にこれを 1.0 のままにしています。
- tracesSampleRate:トラフィックの一断面を取得します。パフォーマンスデータの量を管理するための主要な調整レバーです。
- replaysSessionSampleRate:セッション開始時点から、セッション全体を記録します。高精細(high-fidelity)なので、通常は「平均的な」ユーザーがどうナビゲートしているかを見るには、ごく小さい割合で十分です。
- replaysOnErrorSampleRate:バッファです。エラーが発生した場合にのみリプレイを送信し、エラーに至るまでの 60秒間 のアクティビティを記録します。
精密な制御:tracesSampler
Trace は私たちが持つ指標の中でも特に重要である可能性が高く、パフォーマンス監視、エラー監視、そしてすべてのデータを相互に結びつける役割を担っています。本番環境では、トレースの100%をサンプルすることがほとんどの場合推奨されます。しかし、特にトラフィックが非常に多いアプリケーションでは、戦略的にトレースするのであれば、すべての Trace を収集する必要はありません。
一律の割合を指定する代わりに、Sentry では tracesSampleRate に tracesSampler 関数を渡せます。これにより、リクエストのコンテキストに基づいて、リアルタイムに判断を下せるようになります。
サンプリングコンテキストには何が入っているのか
Span が開始されると、サンプラーは samplingContext オブジェクトを受け取ります。こうしたデータは自動的に利用でき、サンプリングするかどうかを判断するために、必要に応じて自分で渡した情報とあわせて使えます。

tracesSampler 関数では、context オブジェクトをそのまま参照するか、必要な値を直接分割代入して、0〜1 の範囲の戻り値を返します。


Session Replay によるスマートサンプリング
Trace は何が起きたのか、そしてどこで起きたのかを教えてくれます(例: 「データベースが遅かった」)。
また Replays はどのようにそれが起きたのかを教えてくれます(例: 「ローディングスピナーが表示されなかったため、ユーザーがボタンを5回クリックした」)。
デフォルトでは Session Replay は replaysSessionSampleRate に基づいて、全ユーザーセッションのうち一定割合を記録するように設定されています。またバッファ上で動作し、ユーザーがエラーに遭遇した場合にのみ送信される別のサンプルレートもあります。こちらは通常、1.0 か、それに近い非常に高い割合のままにしておきます。

一般的な Sentry のプランでは 500万 spans が含まれている一方で、Session Replay は 50 件から始まります(どちらも追加購入できます)。気にする必要があるのはプラン上のクォータだけではなく、Session Replay の記録はユーザーにとってやや負荷が高いという点もあります。
サンプルレートを設定することは良いスタートですが、本番環境のアプリケーションでは、いつ記録するかについてもう少し意図的に設計したくなることがあります。たとえば、新機能やクリティカルなエクスペリエンスフローの一部など、特定の部分をより頻繁に記録したいと考えることもあるでしょう。
replaysSampler はまだありませんが、replay.start() を使えば、Replay を手動で開始して管理することは可能です。
カスタム useSessionReplay Hook
Session Replay は全体のサンプルレートで設定できますが、Session Replay の取得を自分たちで手動で計測することもできます。
React / Next.js プロジェクトで使えるカスタム React Hook を作ると、ページごとに Session Replay をどの程度の頻度でサンプリングするかを動的に制御できます。
ここではその実装方法を見ていきましょう。
まず、今回は手動実装を行うため、replaysSessionSampleRate を無効化しておくことを忘れないでください。

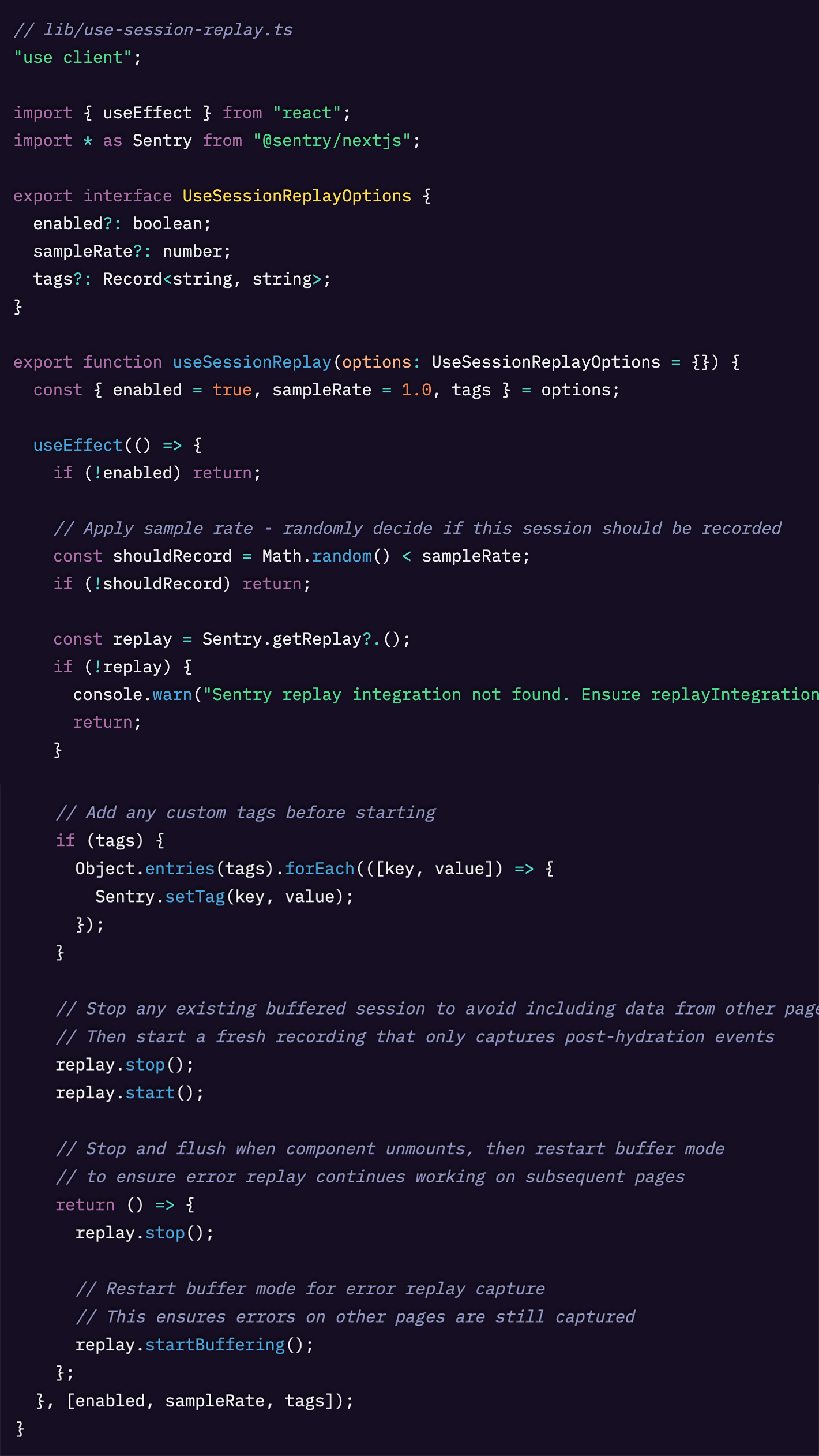
これにより、必要な箇所に合わせて Session Replay を細かく調整でき、重要な追加コンテキストを付与することもできます。
ただし、この方法にデメリットがまったくないわけではありません。この方法ではコンポーネントがマウントされた後に録画が開始されるため、レンダリングのごく初期段階で発生する hydration の問題は取りこぼす可能性があります。もしその部分は見えなくても、Web Vitals では捉えることができます。
Logs はどうでしょうか
Logs は Sentry に比較的新しく追加された機能です。Sentry の初期化設定で enableLogs を有効にすると、SDK の Sentry Logger、または Console Logging Integration のようなインテグレーション経由で、Sentry にログを送信できるようになります。
インテグレーションが有効になっている場合、Sentry はデフォルトでログを100%受け取ります。ただし高トラフィック環境では、Sentry の beforeSendLog や、LogTape と構造化ロギングのような別のロギングツールを使って、送信元でログをフィルタリングすべきです。
私たちは最近、LogTape と Sentry sink を使って、本番アプリにおけるロギングのアプローチをどう改善できるかについて紹介しました。
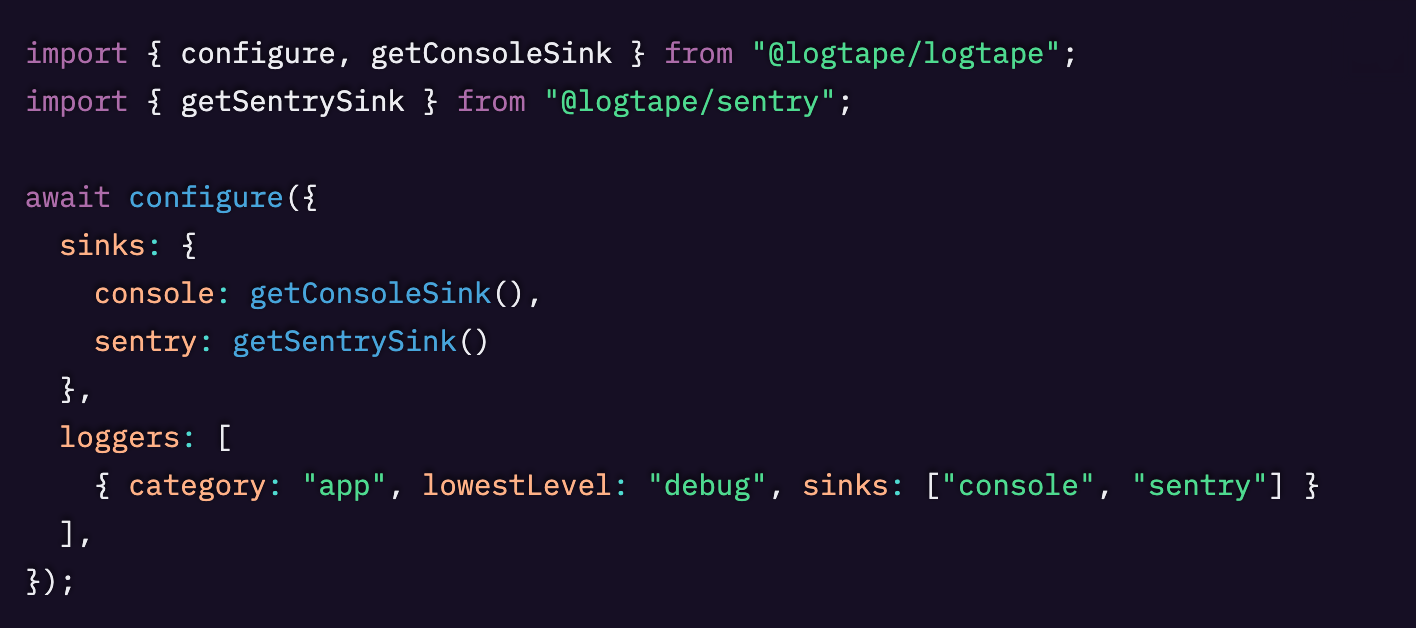
最も基本的なレベルでは「severity」レベルに基づいて、sink ごとに送信するログを制限できます。アプリに debug ログを計測として組み込んでいることもありますが、スケールしてくると、それらはノイズになりやすく、クォータを消費してしまうことがあります。そこで lowestLevel を設定することで、より低いレベルのログを除外するようにできます。
よく設計された構造化ロギングを使えば、特定のデータ属性に基づいて簡単にフィルタリングできます。これはノイズ対シグナルの観点から、送信するデータ(および送信先)を制限・処理するのに役立つだけでなく、データスクラビングにも有効です。
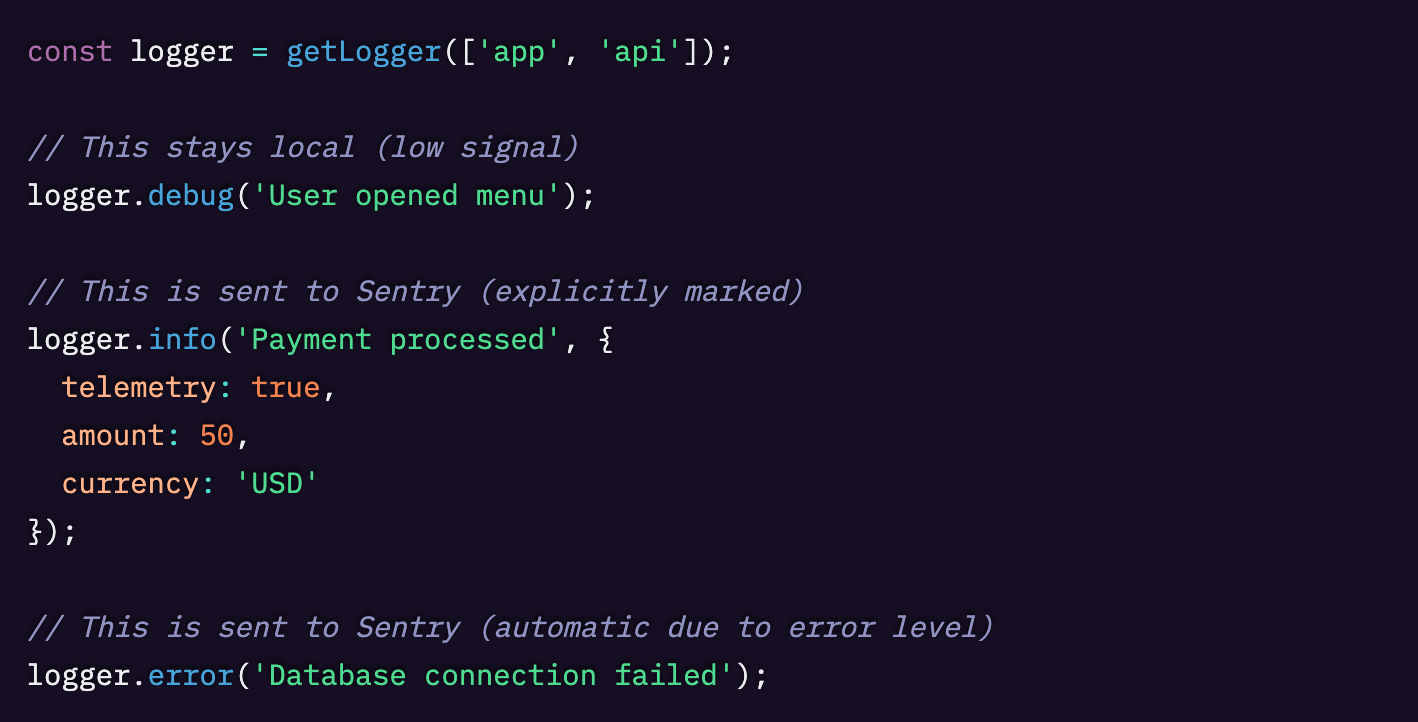
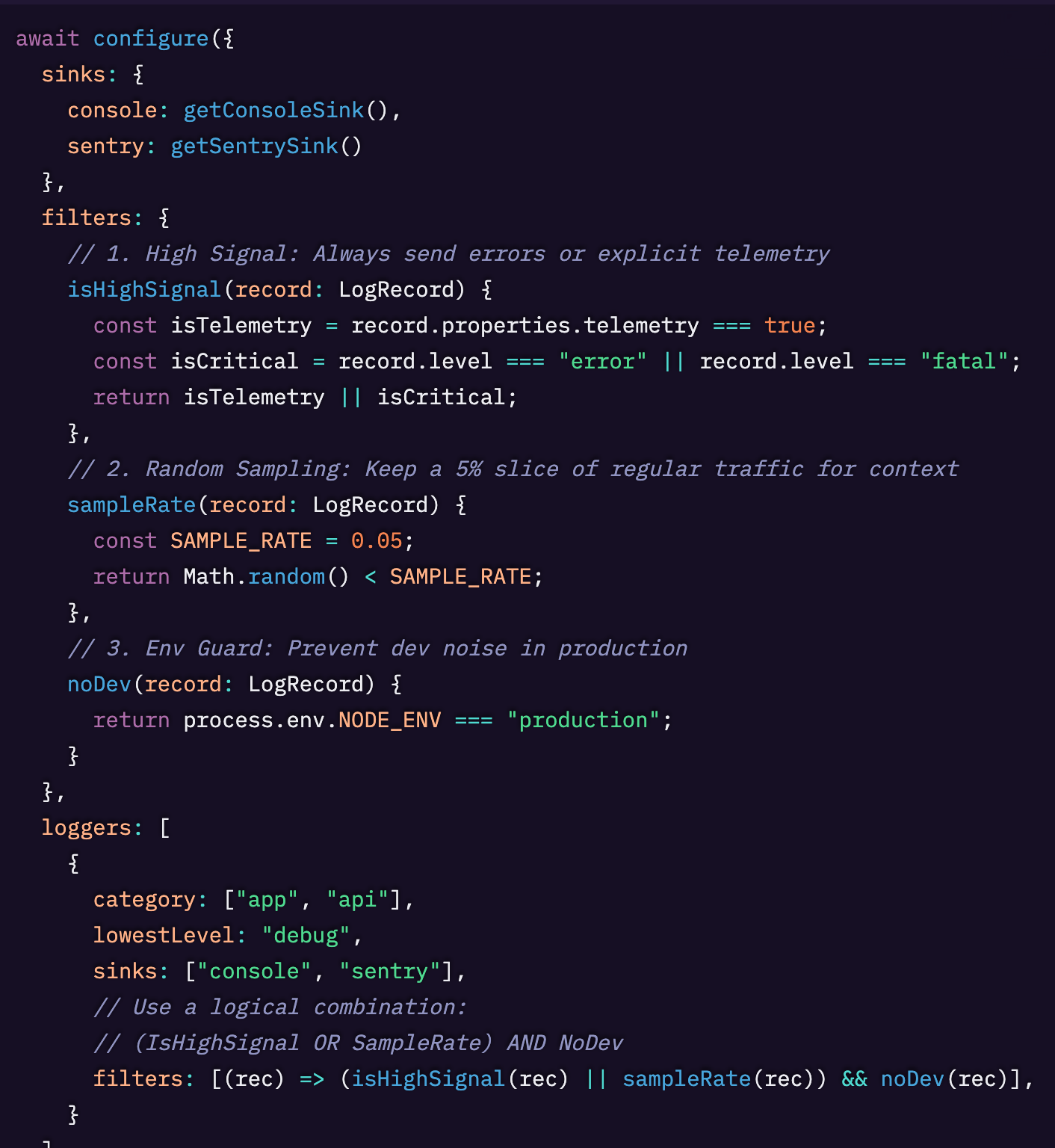
LogTape を使ったログのフィルタリングとクエリ方法については、こちらをご覧ください。
まとめ:スケール環境におけるテレメトリのサンプリング
Sentry の初期設定はシンプルです。SDK を計測できるように組み込み、サンプルレートを 100% に設定すれば、エラー、パフォーマンスデータ、ログ、Session Replay などが流入し始めます。ですが、トラフィックが増え、監視の優先順位が変わってくると、理想的にはノイズをシグナルから切り離して最適化し、必要な箇所に注意を集中できるようにしたくなります。
- Traces:Trace はアプリ内のイベントをマッピングし、相互につなぎます。通常は大半、あるいはすべての Trace を記録したいところですが、十分なトラフィック量がある場合は、影響の大きい対象を優先するのが合理的です。
- Session Replays:Replay は最も高精細なツールですが、その分もっとも負荷が大きい手段でもあります。一律の割合で取得する代わりに、
replay.start()を使って、チェックアウト時や新機能が有効になっている場面など、重要なユーザーフローでのみ録画を開始し、視覚的コンテキストの価値が高い箇所に絞って活用しましょう。 - Logs:
beforeSendLogを使って、severity やカスタムメタデータでフィルタリングします。すべての定常イベントについて「Info」ログを送るのはやめ、構造化ロギングを採用しましょう。そうすれば、ログが Sentry に届く時点で、すでに検索しやすく高シグナルな形に整えられています。
Sentry をまだ使ったことがない場合は、サインアップして始めるか、Logs と Session Replay のクイックスタートガイドを確認してみてください。
FAQ
■なぜ、すべてを100%サンプリングすべきではないのですか?
可能です。特にアプリが小規模だったり、まだ新しかったりする場合は、それでよいこともあります。しかしスケールしていくにつれて、すべてを取得するのは無駄が増え、ノイズも多くなります。本当に重要な100件を見つけるために、定型的な「ボタンがクリックされた」span を100万件も解析するのは効率的ではありません。さらにあらゆる操作はネットワーク負荷として積み重なっていきます。サンプリングを使えば、重要だったり変化が速かったりする箇所では高シグナルなデータに集中しつつ、安定している部分は低いレートに抑えられます。
■tracesSampleRate と tracesSampler の違いは何ですか?
tracesSampleRate は、すべての Trace に一律で適用される固定の割合です。シンプルですが、大まかな制御になります。一方 tracesSampler は関数で、ルート、ユーザー属性、あるいはバックエンド側ですでにサンプリング判断が行われているかどうか、といったコンテキストに基づいて、Trace をサンプリングするかどうかをリアルタイムに判断できます。「すべてを5%サンプリングする」以上の制御が必要であれば、tracesSampler を使いましょう。
■フロントエンドとバックエンドのサンプリング判断を同期させるにはどうすればよいですか?
tracesSampler 関数の中で inheritOrSampleWith を使います。これは、バックエンド側ですでに Trace をサンプリングする判断が行われているかを確認し、行われていればフロントエンドはその判断に従います。上流側の判断がない場合は、指定したレートにフォールバックします。これにより、Trace の一部だけがサンプリングされ、別の部分はされない、といった「orphaned spans(孤立した span)」を防げます。
■Session Replay のサンプリングは Trace サンプリングと同じように制御できますか?
完全に同じようにはできません。replaysSampler 関数は(まだ)ありません。replaysSessionSampleRate と replaysOnErrorSampleRate で静的なサンプルレートを設定するか、コード内で replay.start() を使って Replay を手動で開始できます。ブログ記事には、Replay をいつ取得するかをより細かく制御したい場合のために、カスタム useSessionReplay Hook の例も含まれています。
■Sentry にログを流し込みすぎずにサンプリングするにはどうすればよいですか?
送信前に beforeSendLog を使って、severity やカスタムメタデータに基づいてログをフィルタリングします。さらによい方法として、LogTape のようなツールで構造化ロギングを採用すれば、severity レベル、特定のタグ、あるいはログが明示的にテレメトリ向けとしてマークされているかどうか、といった属性に基づいて、送信元でフィルタリングできます。こうすることで、高シグナルなログだけが Sentry に送られるようになります。
■5%でサンプリングしている場合、問題の5%しか見えていないということですか?
必ずしもそうではありません。サンプリングが影響するのは可視性ではなく、データ量です。エラーは通常 100%(sampleRate: 1.0)でサンプリングされるため、すべての失敗を確認できます。パフォーマンスデータについては、5%でもトラフィックの代表的な断面を取得できます。たとえばチェックアウトが遅ければ、5%のサンプルでも遅いことはわかります。違うのは確認する span の件数が少なくなるだけです。重要なのは、そのサンプルが代表性を持っていることです。そこで影響の大きいルートを優先できる tracesSampler が役立ちます。
Original Page: Watching everything is watching nothing: Sampling strategy for Sentry
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。