
Article by: Kyle Tryon
ここ数か月で私は本気で「ヴァイブ・コーディング」を受け入れはじめ、メインのコードエディタとしては Cursor を、エージェントの LLM としては Claude Sonnet 4 を使っています。開発者にとっていまは刺激的な時代です。私たちは、生産性を100倍にしてくれるかもしれない何かを試しつつ、これらのツールを実装するための新しいワークフローや戦略を切り拓いているのです。
しかし、十分に大きなコードベースで LLM を使った本格的な開発をしたことがある人なら誰でも知っているとおり、それは「怯えた猫の群れをまとめようとするようなもの」です。
コードベースが複雑化・分散化するほど、管理すべきコンテキストは増え、ファイル固有のルールも増え、エージェントから高品質な出力を得ることが全般的に難しくなります。皮肉なことに、私たちがコードをきちんと整理すればするほど、LLM はそれを見つけるためのコンテキスト管理タスクをより多くこなさなければならなくなります。
PR のレビューやテスト生成といった AI ツール一式があっても、AI 生成コードを出荷するのは不安が残ります。ヴァイブ・コーディングで作った機能が本番を落とさないと、どうして言い切れるでしょうか。そもそも本当に動くのか、どうやって確かめればよいのでしょう。ビルドを通すためだけに、エージェントが巨大なコード片をコメントアウトしてしまうのを目にしたことさえあります。
エージェント主導のコードサイクルには盲点があります。しかし、それは修正可能です。
LLMの盲点:実行時の可視性
 プロンプトを微調整したり、docstring を追加したり、エージェントのルールを洗練させたりしても、核心的な問題は解決しません。LLM は、自分が生成したコードが実際に走ったときに何が起きるのかを「見る」ことができないのです。暗闇の中で手探りでダーツを投げ、修正を重ねても照準を合わせ直せない。しかも、生成コードに現れたエラーは、LLM がその問題を見ないまま反復するほど増殖していきます。
プロンプトを微調整したり、docstring を追加したり、エージェントのルールを洗練させたりしても、核心的な問題は解決しません。LLM は、自分が生成したコードが実際に走ったときに何が起きるのかを「見る」ことができないのです。暗闇の中で手探りでダーツを投げ、修正を重ねても照準を合わせ直せない。しかも、生成コードに現れたエラーは、LLM がその問題を見ないまま反復するほど増殖していきます。現状のコンテキスト管理は、プロンプトにどのファイルを含めるかの管理に大きく依存しています。MCP(Model Context Protocol)は一歩先に進み、複数のデータソース間でコンテキスト情報をやり取りできるようにしてくれます。
いま Cursor や Claude Code のようなツールを、MCP 連携が限定的な形で使っているなら、あなたのコンテキストはおそらくアプリのソースコードと、多少のドキュメント、それにコピペした何かくらいに留まっているはずです。
コードを実行し、そのログを問題解決のために手動で LLM に食べさせたことがあるかもしれません。目指すべきはここにフィードバックループを組み込むことです。すなわち、コードを生成し、その実行からテレメトリ(計測情報)を収集し、その結果を LLM に知らせることで、ガイダンス付きで解法の反復を進められるようにするのです。
このフィードバックループをどう閉じるかを理解するために、まずトレースとは何か、そしてそれが欠けている「実行時の可視性」をどう提供できるのかを見ていきます。MCP サーバーを使えば、この重要なコンテキストを LLM エージェントに追加し、可視性のギャップを埋めることができます。

この例では、ユーザーが /stash/category/movies/ というページへ遷移し、そこから起動した後続の処理が合計 0.568 秒で完了したことが分かります。
時間のほとんどはデータベースクエリに費やされています。db.select.library_entries クエリは、次に長いクエリの 2 倍の実行時間です。もし最適化に注力するなら、まずはそこから着手するのがよいでしょう。データベースクエリが終了したあと、フロントエンドは多数の画像を取得します。詳しく掘り下げると、それらはローカルキャッシュされていることが分かります。
しかし本当に必要なのは、この種のデータを LLM にフィードバックとして渡し、結果を自動的に分析して、必要に応じて修正を加えられるようにすることです。

認証が完了すると、MCP サーバーは、まだ有効化されていない場合にアプリへトレースを自動で計装するための Sentry ドキュメントと、アプリ実行時の挙動に関する追加コンテキストを取得するためにエージェントが呼び出せる各種ツールを提供します。
これで、エージェントに対してアプリの最新イベントを要約・調査するよう依頼できます。速度と正確さのため、私は調査したい特定のトレース ID またはスパン ID を渡す方法を好みますが、次のような検索でも構いません。


正しく構成されていれば、エージェントが追加コンテキストを取得するために MCP 提供のツールを使うべきだと理解していることが分かるはずです。

返答(私の場合は Claude Sonnet 4 によって生成)は、発生した事象をタイミング情報付きで段階的に分解し、特に画像の読み込みを中心に、パフォーマンス改善の可能性についての提案を示してくれました。
より良いヴァイブ・コーディングのワークフロー
ループを閉じ、アプリケーションの完全な可視性をエージェントに与えましょう。ソースコードだけでなく、「そのコードを実行した結果」も含めます。以下は、ヴァイブ・コーディングのアプリで新機能を実装するときに私が使っているワークフローです。
1. 計画ドキュメントを作成する
新しいブランチで計画ドキュメントの下書きを始めます。これは LLM のコンテキストウィンドウを超えて残る永続的なアーティファクトとなり、変更の追跡や前提の検証を容易にします。
プロンプト例

2. 機能コードを生成する
計画ドキュメントの準備ができたら、コンテキストがクリアな新しいチャットを開き、そのドキュメントを読み込ませます。LLM に、記載どおりに計画を実装するよう依頼します。
この種の長い処理では、Cursor のバックグラウンドエージェントを使うのが好みです。大きな介入なしにほぼ無人で走らせておけます。あわせて、エージェントにファイルベースのルールを活用し、アプリの重要コンポーネントに対する具体的なコンテキストと指示を与えましょう。
3. ステージングにデプロイしてテストする
ステージング環境(またはローカルの開発サーバー)にデプロイし、新機能を試験します。昔ながらの QA テストです。コードが(読む以外に)完全な粗大ごみではないことを確かめる最も簡単な方法は、実際に動かしてみることです。
まだアプリに Sentry の計装を入れていない場合は、デプロイとテストの前に実施してください。テスト中に起きる事象のメトリクスを収集するためです。Sentry の初期化時に Environment タグを設定すれば、本番/ステージングなどを区別してフィルタできます。
4. 分析して反復する
最後に、データを用いてフィードバックループを閉じる重要なステップです。いま私たちの手元には、LLM が当初達成しようとしていた内容を記述した計画ドキュメントがあり、トレーシングを有効にした状態でそのコードを実行し、実際に何が起きたかを検証できる状態です。
ここで、Sentry から得たトレースデータを計画ドキュメントと突き合わせ、すべてが計画どおりに進んだかを LLM に検証させます。呼び出されなかった関数、実行されなかったデータベースクエリ、捕捉されたエラーがないかを確認します。
トレース検証用プロンプト例
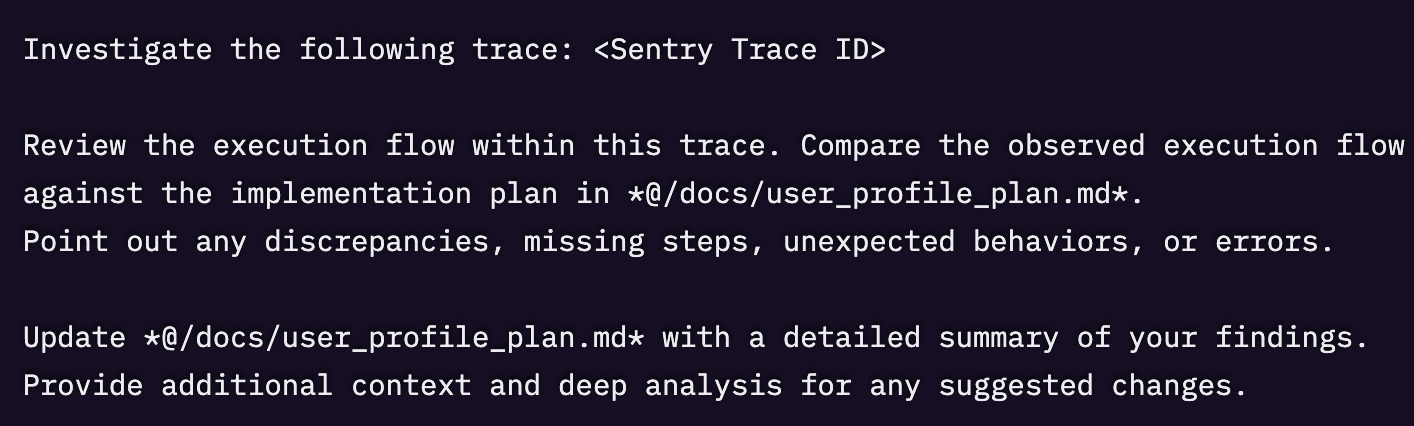
5. 仕上げ(ガードレールの整備)
ランダムなカオスとの戦いを忘れてはいけません。私たちの最良の武器は、多層の自動チェックと検証、そして人間です。ふだんの CI ワークフローを回しましょう。linter、型チェッカー、フォーマッター、ユニットテスト、統合テスト、E2E テストなど。
Sentry はプルリクエスト向けのテスト生成と自動レビューの双方にも対応できます。良質でクリーン、効率的かつコンポーザブルなコードが生成できたと確信できたら、テストでそれを守ってください。テストは、退屈さや運用慣行のまずさから軽視されがちです。計画ドキュメントとコード変更をコンテキストに含めれば、かなり高品質なテストを自動生成することが可能です。
将来のエージェント主導コードワークフロー
近い将来にエージェント主導の開発フローがどんな姿になるのかを正確に予測できる人はいないでしょう。ただし、物事を模索していく中で多少の柔軟性を帯びるにしても、良いソフトウェアと CI の実践を捨てることはない、という前提は安全に置けます。
おそらく、現在のプラクティスをより大規模に、より厳密なガードレール付きで採用する方向に進むはずです。コードカバレッジの % はついに重要な指標になるでしょうか? linter で docstring の記述を強制し始めるでしょうか? AI エージェントが高度化するにつれ、これまで「あると良い」程度に見なされていた実践が、マシンスピードでコード品質を維持するために不可欠になる可能性があります。
ここまでに組み上げたフィードバックループは、正しい方向へ踏み出した最初の一歩にすぎません。Sentry は最近、Seer という AI エージェントをリリースしました。これは、アプリのスタックトレース、コミット履歴、ログ、エラー、トレースといった完全なコンテキストを用いて、発生した本番障害を自動的に修正します。

【近日開催ワークショップ】フロントエンド改善:パフォーマンス監視のベストプラクティス
RSVP:https://luma.com/svmryn3f
Seer は、新たに捕捉されたエラーに反応して自動でプルリクエストを生成するように構成できます。続いて、GitHub Copilot や Sentry の @sentry review のような AI ツールが、その PR 上でコード提案を行います。納得いくまでレビューを再リクエストして変更をマージし、最後は @sentry generate-test で新しいテストを追加して仕上げる。すべてを PR から離れずに実行できます。
私たちは「祈り頼み」の LLM エージェント開発の時代を越え、強化学習に学ぶ発想で前進しています。すなわち、エージェントが自らの行動を観測し、その結果から「学習」して継続的に改善できるように、フィードバックループを導入するのです。
私たちは、今後 10 年の開発と CI の実践の地平を切り開いています。明日のソフトウェアの作られ方を形作る、稀有で刺激的な機会です。
Original Page: Vibe Coding: Closing The Feedback Loop With Traceability
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。

