Article by: Sergiy Dybskiy
「エージェントのオブザーバビリティのベストプラクティス」を謳うコンテンツのほとんどは、2019年のコンプライアンスチェックリストの「マイクロサービス」という部分を「AI」と貼り替えただけのようなものです。「包括的なロギングを実装する」「評価メトリクスを確立する」「ガバナンスフレームワークを構築する」など、コードは一行も出てこず、エージェントが3ターン目にこっそり間違ったツールを選んでしまったとき、なぜそうなったかを突き止める方法にも一切触れていません。
エージェント監視に必要なものは2つです。すべてのエージェントで何が起きているかを示すダッシュボードと、特定の実行でなぜ問題が起きたかを正確に示すトレース。ほとんどのツールはどちらか一方しか提供しません。両方を持っている場合どうなるか、見ていきましょう。
エージェントのオブザーバビリティとは何か
エージェントのオブザーバビリティとは、AIエージェントの動作をエンドツーエンドで可視化することです。どのモデルを呼び出しているか、どのツールを実行しているか、各ステップでどんな意思決定をしているか、そしてその決定が最終的な出力にどう影響しているかを把握できます。
従来のアプリケーション監視はリクエスト、エラー、レイテンシを追跡します。各リクエストが独立したステートレスなHTTPサービスではそれで十分です。
しかしAIエージェントは異なります。単一のエージェント実行には、複数のLLM呼び出し、ツールの実行、サブエージェントへのハンドオフ、マルチターンの推論ループが含まれることがあり、これらすべてが互いに依存し合っています。出力が誤っていた場合、その連鎖のどこかに失敗が潜んでいる可能性があります。ツールからの不正なレスポンス、コンテキストウィンドウのオーバーフロー、モデルによる間違った関数の選択、ハンドオフでのステート消失など、原因はさまざまです。
従来の監視がAIエージェントで機能しない理由
標準的なAPMツールは「POST /api/chat が4.2秒で200を返した」とは教えてくれます。しかし、そのリクエストの中でエージェントが5回LLMを呼び出し、3回目に間違ったツールを選択し、そのツールが古いデータを返し、モデルがそのゴミを律儀に要約したというようなことは教えてくれません。
「とにかく全部ログに残して後で考える」という監視方針であれば、カウントと平均値で埋まったダッシュボードができ上がるだけで、深く掘り下げる手段はありません。間違った答えを返したエージェントは、12回LLMを呼び出し、4つのツールを実行し、サブエージェントにハンドオフしてからゴミを生成していたかもしれません。集計メトリクスはエラーレートが上がったことは教えてくれても、推論のどこでおかしくなったかは教えてくれないのです。
必要なのは、標準的な規約に基づいて設計された構造化トレースです。ダッシュボード、トレース、アラートがすべて同じ言語で話せるようになります。
エージェントオブザーバビリティのOpenTelemetry標準
OpenTelemetryの gen_ai セマンティック規約は、AIエージェントシステムのインストゥルメンテーション標準を定義しています。カスタムロギングの代わりに、すべてのAI操作が一貫した属性セットを持つ構造化スパンを生成します。規約で定義されたコアオペレーションは以下の通りです。
スパンオペレーション | 何をキャプチャするか |
|---|---|
| 単一のLLM呼び出し:モデル、プロンプト、レスポンス、トークン数 |
| エージェント実行のフルライフサイクル:タスクから最終出力まで |
| ツール/関数呼び出し:名前、入力、出力、実行時間 |
これらはスパンツリーとして構成されます。
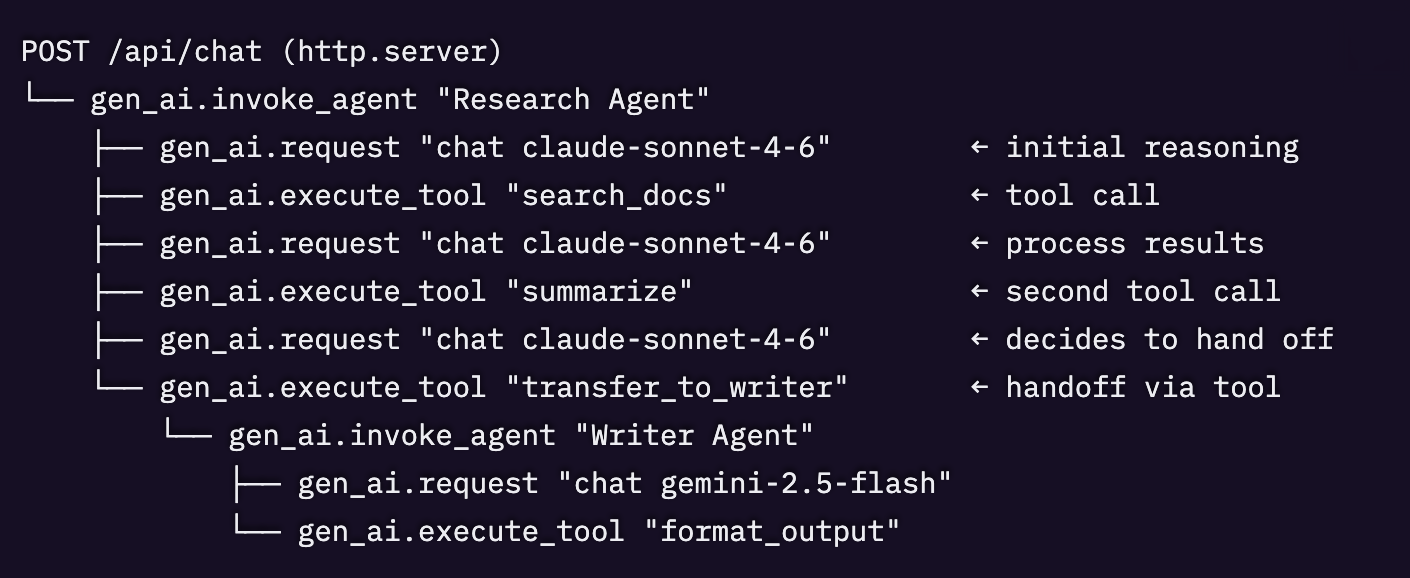
gen_ai.{operation_name} というパターンに従います。手動インストルメンテーションの場合、gen_ai.request がすべてのLLM呼び出しをカバーします。SDKによる自動インストルメンテーションでは、呼び出されるAPIに応じて gen_ai.chat や gen_ai.embeddings といったより具体的なopが生成されることもあります。これらは非構造化ログではなく構造化スパンであるため、ダッシュボードとトレースビューの両方を活用できます。AIエージェント監視の主要メトリクス
ツールの話に入る前に、本番環境のAIエージェントで追跡すべき指標を整理しておきましょう。
信頼性メトリクス
- エージェントエラー率 — 失敗またはエラーを返したエージェント実行の割合
- ツール失敗率 — どのツールが信頼性に欠けるか、またどれほどの頻度でエージェント実行を壊すか
- レイテンシ(p50、p95) — エージェントごと、モデルごとに計測し、リグレッションや性能劣化を検知する
コストメトリクス
- トークン使用量 — モデルごとの入力・出力・キャッシュ済み・推論トークン数。キャッシュ済みトークンと推論トークンは合計の内訳であり、加算するものではありません。ここを誤ると、コストダッシュボードはまったく意味をなさなくなります。
- モデルごとのコスト — 同様の処理をしているモデルを比較してみましょう。
claude-sonnet-4-6が週あたり$10,800かかっているのに対し、gemini-2.5-flash-liteが同じ量を$645でこなせることに気づくかもしれません。 - ユーザー/プランごとのコスト — どのユーザーや料金プランがAIリソースを最も消費しているか。
品質メトリクス
- ツール呼び出し頻度 — エージェントが各ツールをどれくらいの頻度で、どの順番で呼び出しているか。
- トークン効率 — エージェントが正常完了するまでの平均トークン数。この数値が増加傾向にある場合、プロンプトやコンテキストウィンドウが肥大化している可能性があります。
- キャッシュヒット率 — 入力トークンのうちプロンプトキャッシュから提供された割合。キャッシュを有効にしているのにこの数値が改善されない場合は何か問題があります。
これらのメトリクスの詳細や重要性については、LLMパフォーマンスのコアKPIメトリクスに関する記事が参考になります。OpenTelemetryの規約に従うエージェントオブザーバビリティプラットフォームであれば、トレースデータからこれらの指標を自動的に抽出できるはずです。
ここからは、Sentryを例に実際の運用イメージを見ていきましょう。
10以上のフレームワークに対応した自動インストルメンテーション
SentryはPythonおよびNode.jsの主要なAIフレームワークを自動インストルメンテーションします。対応フレームワークにはOpenAI、Anthropic、Google GenAI、LangChain、LangGraph、Pydantic AI、OpenAI Agents SDK、Vercel AI SDKなどが含まれます。スパンを手動で作成する必要はありません。パッケージをインストールしてトレースを有効にするだけで、Sentryが自動的に検出します。
セットアップはこれだけです。


AI Agentsモデル詳細

AI Agentsツール詳細


「どの料金プランがAI予算を圧迫しているか?」
ユーザーにプランのタグを付けて、そのタグをもとにダッシュボード上でグループ化しましょう。


こうすることで、無料プランのユーザーがAI予算の60%を消費していることを把握できます。同じタグ付けのパターンは、team、feature_flag、experiment_group など、あらゆるディメンションに応用できます。
「トークンを大量消費しているエージェントはどれか?」

「Research Agent」が1回の実行あたり平均15,000トークンを消費しているのに対し、「Summarizer Agent」が平均2,000トークンであれば、プロンプト最適化をどこに集中すべきかが明確になります。
「プロンプトキャッシュは本当にコスト削減に効いているか?」

Anthropicのプロンプトキャッシュを有効にしてもキャッシュ済みトークンと総トークンの比率が改善されない場合は、プロンプトの構造に問題があります。
トレーシングがエージェント監視に欠かせない理由
ダッシュボードは集計値を示し、トレースは意思決定を示します。
ダッシュボードはエラー率の上昇やレイテンシのスパイクを教えてくれます。トレースは、どのエージェントの、どのモデル呼び出しの、どのツールが原因だったかを教えてくれます。
分散トレーシングはすでにリクエスト全体のスパンツリーをキャプチャしています。ブラウザのインタラクション、HTTPコール、サーバーサイドのルーティング、データベースクエリなどです。エージェントのオブザーバビリティはこれに接続します。gen_ai.* スパンは既存のトレース内の子スパンとして表示されるため、LLM呼び出し、ツール実行、MCPサーバーとのやり取り、サブエージェントへのハンドオフが、通常のアプリケーションスパンと並んで確認できます。別途システムを用意する必要はありません。
これこそがトレーシングの強みです。エージェントのデータを単独で見るのではなく、ユーザーのクリックから最終的なツールのレスポンスまで、エージェントの意思決定をスタックの一層として含んだリクエスト全体を俯瞰できるのです。
Sentryのトレースビューではこのようになります。

ブラウザのクリックからLLM呼び出し、MCPサーバーとのやり取り、エージェントのハンドオフまで、エージェントワークフロー全体を示す分散トレース
1つのリクエストをエンドツーエンドで確認できます。ユーザーがブラウザで「Send Message」をクリックした瞬間から、APIレイヤーを経てLLM呼び出しとMCPサーバーとのやり取りを含むエージェントオーケストレーションへ、そして2つ目のエージェントへのハンドオフまで。任意のスパンをクリックすると、モデル、トークン数、コスト、システムプロンプトを確認できます。
エージェントオブザーバビリティのベストプラクティス
どのプラットフォームを使う場合でも、以下を実践しましょう。
- ログではなく構造化トレーシングを使う。 非構造化ログでは推論チェーンを再現できません。OpenTelemetryの
gen_aiスパンを使えば、ダッシュボードとトレースビューの両方を同時に活用できる、検索・フィルタリング可能なスパンツリーが得られます。 - AIトレースは100%サンプリングする。 エージェント実行はスパンツリーです。サンプリングによって個々の呼び出しではなく、実行全体が欠落します。
tracesSampleRateが1.0未満の場合、エージェント実行の一部が完全に失われています。tracesSamplerを使ってAIルートは100%、それ以外はベースラインのサンプリングレートで維持しましょう。 - コストはモデル単位だけでなく、ユーザー単位で追跡する。 プリビルドダッシュボードはモデルごとの合計を表示しますが、レート制限、価格設定、モデルルーティングといったビジネス上の意思決定にはユーザー単位・プラン単位のコスト帰属が必要です。
- ツールの信頼性を個別に監視する。 5%の失敗率を持つツールは全体的なエラー率には現れないかもしれませんが、20回に1回のエージェント実行で不正な出力を生み出しています。エージェント監視ダッシュボードでは、ツールごとのエラー率を個別に確認できるようにしておきましょう。
- AIの監視をフルスタックに接続する。 エージェントの失敗は、遅いデータベースクエリ、外部APIの呼び出し失敗、フロントエンドのタイムアウトが原因である場合があります。AIの監視を独立させると、こうした根本原因を把握できません。
フルスタックのエージェントオブザーバビリティ
エージェントのオブザーバビリティが最も効果を発揮するのは、フルAPMプラットフォームの上に構築され、エージェントスパンがスタック全体のエラー、パフォーマンストレース、セッションリプレイ、ログと連携しているときです。
AIの監視だけを独立させると、gen_ai スパンがサイロに閉じ込められます。Research Agentが8回LLMを呼び出して$0.04かかったことはわかります。しかし、3回ではなく8回呼び出した理由(search_docs ツールが低速なPostgresクエリにヒットしてタイムアウトし、エージェントが毎回クエリを言い換えてリトライしていた)はわかりません。
エージェントスパンがスタックの他の部分とコンテキストを共有していれば、全体像が明らかになります。エラーはスパンツリー全体とともに表示されます。セッションリプレイは、不正なエージェント実行を引き起こしたユーザーの操作を示します。上流のインフラの問題(劣化したベクターデータベース、不安定な外部APIなど)が、それによって引き起こされたエージェントの挙動と同じトレース上に表示されます。
最初のトレースまで4ステップ
- SDKをインストールする:
pip install sentry-sdkまたはnpm install @sentry/node - トレーシングを有効にして初期化する
- AIを呼び出す。スパンとダッシュボードが自動的に反映される
- (オプション)AIアシスタント用のCLIスキルをインストールする

Sentryを無料で試す — AIの監視はすべてのプランに含まれています。
AIエージェント監視に関するFAQ
■ エージェントのオブザーバビリティとは何ですか?
エージェントのオブザーバビリティとは、AIエージェントの動作をエンドツーエンドで可視化することです。モデルの呼び出し、ツールの実行、意思決定の連鎖、ハンドオフ、トークン使用量、コストなどを網羅します。マルチターンのやり取りを通じた推論チェーン全体を追跡する点で、従来の監視を超えるものです。
■ エージェント監視とLLM監視の違いは何ですか?
LLM監視は個々のモデル呼び出し(レイテンシ、トークン、エラー)を追跡します。エージェント監視はエージェントのフルライフサイクルを追跡します。マルチステップの推論、ツールの実行、エージェント間のハンドオフ、そして個々のLLM呼び出しが完全なワークフローとしてどう組み合わさるかまで把握できます。
■ AIエージェントで追跡すべきメトリクスは何ですか?
最低限として、エージェントエラー率、ツール失敗率、レイテンシ(p50/p95)、モデルごとのトークン使用量、ユーザー/プランごとのコスト、キャッシュヒット率を追跡しましょう。これらは信頼性(正常に動いているか?)、コスト(いくらかかっているか?)、品質(改善されているか?)の3つの観点に分類できます。
■ エージェントのオブザーバビリティに対応しているツールは何ですか?
OpenTelemetryの gen_ai セマンティック規約が事実上の標準として台頭しています。Sentry、LangSmith、Langfuse、Arize、Datadogはいずれもエージェントのオブザーバビリティを提供していますが、アプローチはそれぞれ異なります。Sentryの差別化ポイントはフルスタックのコンテキストです。AIエージェントのデータが、エラー、パフォーマンストレース、セッションリプレイ、ログと1つのプラットフォーム上で連携しています。
Original Page: AI agent observability: The developer’s guide to agent monitoring
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談は「お問い合わせ」からお気軽にお問い合わせください。