
Article by: Milin Desai
最近、ある企業の開発責任者(会社名は出せないのですが)からこんなふうに言われました。
「あなたのおかげで、本当にユーザーに影響を与える問題を見つけて解決できました。次は、それが標準的な SLO やシステム指標よりも重要だということを CTO に納得してもらう必要があります。」
CTOがシステムと基本的な稼働時間を測定するのは間違いではありません。ただ、それは基準線にすぎません。だれもがあらゆるものを監視しようとしていますが、ユーザーに関係することについては何も見えていないのです。
従来型モニタリングの罠
稼働率は素晴らしい。レイテンシはSLOの範囲内。エラーバジェットも問題ない。ダッシュボードは緑一色。
それでも、ユーザーはまだ失敗しています。システムが落ちているからではありません。システム自体は問題ないのです。けれども「ユーザーがボタンをクリックする」から「ユーザーが欲しかった結果を得る」までのどこかで、何かが壊れました。静かに。
アラートは出ない。しきい値も超えない。ただ、ユーザーが諦めて離脱しただけです。
コードは壊れます。そこが問題の核心ではありません。問題は、それが3週間後に発覚することです。大口の顧客が苛立って離脱しそうになり、営業チームがエスカレーションして初めて分かるのです。
マネーモーメント
どのプロダクトにも「マネーモーメント」がいくつかあります。ユーザーが成功できるか、あるいは収益を失うかを左右する、プロダクト内の特に重要なポイントです。「APIは落ちていないか」でも「ページは読み込めたか」でもありません。ユーザーが本当にやりに来た「その行為」のことです。
最近聞いた例をいくつか挙げます。
ある小売企業はブラックフライデーを完璧な稼働時間で乗り切りましたが…
コンバージョン率が12%も下がってしまいました。マネーモーメントである「購入手続きの完了」が、特定のブラウザ拡張機能を使っているユーザーで機能していませんでした。サーバーエラーはなし、アラートもなし。3週間分の売上を失いました。修正にかかったのは1時間ですが、問題に気づくまでには非常に長い時間がかかりました。
ある決済企業はすべてのSLOを満たしていましたが…
顧客から「ランダムに失敗する」という苦情がありました。マネーモーメントである「送金が実際に完了し、確認まで終わること」が、国際送金では断続的に失敗していたのです。原因はタイムアウトのエッジケースで、ダッシュボードには平均値しか表示されていませんでした。影響を受けていたのはユーザーでした。修正は6行のコードで済む内容でしたが、何か月分ものノイズの下に埋もれていました。
あるB2Bプラットフォームはどの指標でも健全に見えていましたが…
ところが、マネーモーメントである「新規顧客が“なるほど”と実感する瞬間」が、特定の設定を持つエンタープライズアカウントで壊れていました。監視より先に営業がそれを見つけました。ダッシュボードはどれもシステムが「稼働中」だと言っていましたが、プロダクトは壊れていたのです。
毎回、同じパターンです。
測っている対象が間違っています
違いはこうです。
多くのチームが測っていること
- すべてのサービスは動いているか
- 指標はしきい値の範囲内か
- システムは健全か
本当に重要なこと
- ユーザーは目的を達成できたか
- できていないなら、どのコードが壊れたのか
- どれだけ早く直せるか
前者は横方向です。あらゆるものを監視して、何かを拾えることに期待する。
後者は縦方向です。マネーモーメントをエンドツーエンドで追う。壊れたらすぐに分かる。リリースまでたどる。修正する。
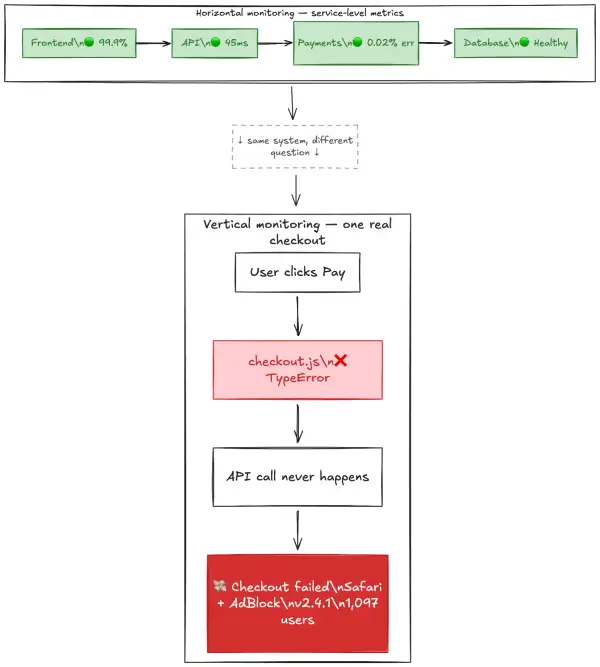
両方を行うこともできます。もしダッシュボードが緑でもユーザーが失敗しているのであれば、何が欠けているかがわかります。
実践するべきこと
複雑ではありません。
- マネーモーメントに名前を付けましょう
50もの異なるフローではなく、プロダクトが機能するかどうかを左右する3〜5つのポイントを特定してください。ユーザーにとって重要で、彼らが目的を達成できるかどうかを左右する瞬間です。ユーザーが成功する瞬間、離脱する瞬間はどこでしょうか。 - セグメント別に監視しましょう
平均ではなく、顧客ティア別、地域別、デバイス別、リリース別です。最大の顧客を混乱させるバグは、集約されたメトリクスには現れません。 - リリースと結びつけましょう
マネーモーメントが失敗した場合、最初にすべき質問は「何が変わったか」です。数分で答えられないようであれば、目を閉じたまま飛んでいるようなものです。 - アラートまでの時間ではなく、修正までの時間を測りましょう
誰もダッシュボードがどれだけ早く真っ赤になったかには関心がありません。壊れたコードをどれだけ早く発見し、修正をリリースできたかが重要です。
これは理論ではありません
ダッシュボードだけでなくマネーモーメントを監視するチームは、いつも同じ結論にたどり着きます。
あるSaaS企業はAPMツールを3つ入れていましたが、実際のユーザーフローはまったく見えていませんでした。非同期キュー、メッセージング層、永続化層にまたがって、ある呼び出しが本来1回のはずなのに8回発火しているのを、開発者が見つけました。マネーモーメントをエンドツーエンドで追えるようになると、数分で修正できました。以前なら、ログを掘り続けて数日かかっていたはずです。
あるインフルエンサーマーケティングプラットフォームは、パワーユーザーにだけ影響する50秒のページ読み込みを見つけました。そのせいで、最重要のワークフローの1つにアクセスできなくなっていたのです。サービスの健全性を見るだけでなく、ユーザーフローをトレースしたことで、5分で問題のリリースを特定し、1時間以内に修正できました。
- 200以上のマイクロサービスを持つ語学学習アプリでは、デバッグ時間を12分の1に短縮しました。あるエンジニアがボット活動に気づき、10分未満で確認できました。サイトが止まるほど遅くなってユーザーを失う前にです。「人生の数年分が救われた」と語っています。
- 世界最大級のAI研究企業の1社は、モデル学習中に起きる、表面化しにくいクラッシュループをより検知できるようになり、モデルからモデルへ進化させるプロセスを大幅に高速化しました。インフラ指標だけでなく、実際のユーザー体験を監視したことが違いを生みました。
毎回同じパターンです。マネーモーメントが壊れた場所が見えるようになった瞬間、修正そのものは単純でした。
結論
コードは壊れます。昔からそうであり、今後もそうでしょう。
成功するチームとは、ダッシュボードがいつも緑色なチームではありません。壊れている箇所をいち早く発見し、ユーザーが気付く前に修正するチームです。
Original Page: Green dashboards, red flags
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。

