Article by: Richard C.
5つのサービス、キュー、そして自分が所有していないデータベースに触れるリクエストをデバッグしようとしたことがあるなら、分散システムの監視がなぜ難しいのかはすでにご存じでしょう。
ログはそれぞれ別の場所に存在し、リクエストはフローの途中で見失われ、そして本番環境で何かが壊れると、断片から何が起きたのかを再構成することになります。
マイクロサービスは設計上これをさらに悪化させます。1つのリクエストが、小さく独立してデプロイされる複数のサービスへと広がり、しばしば非同期にやり取りします。そして、リクエストが自分が管理しているサービスを離れた瞬間に、可視性は通常、急激に落ち込みます。
このガイドでは、Sentry のトレーシングとロギングを使ってリクエストをエンドツーエンドで追跡し、本番環境では通常あまりに時間がかかりすぎる次の疑問に答えられるようにする方法を紹介します。
- このリクエストは実際にどこへ行ったのか
- どのサービスが遅延させたのか、あるいは失敗したのか
- ログを手作業でつなぎ合わせずに、それをどうやって確認すればよいのか
前提条件
マイクロサービスの経験は不要です。この記事を理解するうえで、Web サービスを書いた経験があると役立ちます。
チュートリアルに沿って進めるには以下が必要です。
Docker:サンプルアプリの実行に Docker を使用します。Docker を使うことで、プログラミング言語の各種バージョンをインストールしなくても、どのOSでもアプリが動くことが保証されます。また、個人ファイルから安全に隔離されたセキュアなサンドボックス内で実行できます。
Sentry アカウント:サンプルアプリケーションを Sentry のプロジェクトのいずれかに接続したい場合、Sentry アカウントが必要です。
また少しわかりやすくするために、実行が必要な操作には ▶️ を付けています。
サンプルケーススタディ
この例は意図的にシンプルにしていますが、実際のシステムはもう少し複雑です。
ただし失敗の起こり方は同じです。リクエストは複数の先へ広がり、処理は非同期に進み、何かが壊れると元のコンテキストはたいてい失われています。
では簡単な例を使って、マイクロサービス設計がどのように、そしてなぜ機能するのかを確認しましょう。たとえば、ユーザーが「作る必要のある商品」を注文できるウェブサイトがあるとします。商品は物理的な3Dプリントの物体から、デジタルの納税証明書まで、何でもあり得ます。
現時点ではプロセス全体を処理し、すべてのデータを1つのデータベースに保存するモノリシックな Web サーバーがるとします。
設計は次のとおりです。


各サービスは他のサービスのアドレス(URL)を把握しています。たとえば order サービスが factory サービスに商品の製造開始を依頼したい場合、order サービスは HTTP の POST リクエストで factory サービスを呼び出します。
ところが、ウェブサイト側のチームは「order サービスの応答が遅く、ユーザーリクエストへの応答がそのせいで詰まっている」と不満を持つようになります。そこで、サービス同士が直接・同期的に呼び出し合うのではなく、通信はすべて RabbitMQ のようなメッセージキューを介して行うことにしました。
メッセージキューがどう動くかを示すため、次の例を考えます。
Web サーバーは応答を待たずに、order サービスのキューへ「注文を作成する(create order)」メッセージを投入します。order サービスは、処理できる状態になったタイミングでキューからそのメッセージを取り出し、注文の受け取り準備ができたら、web サービスのキューへレスポンスメッセージを投入します。どのサービスも他のサービスのアドレスや状態を知る必要はありません。各サービスは RabbitMQ とだけ会話します。
システムは次のようになります。

この設計はマイクロサービスアーキテクチャの要件を満たしています。各サービスは小さく目的が明確で、データベースと Git リポジトリを分けることで独立してデプロイでき、さらに非同期のメッセージキューを使うことで自律的に動作します。
さらに柔軟な設計
この設計はさらに柔軟にすることもできます。たとえば factory チームと order チームは、リクエスト数が増えたときにサービスのインスタンスを追加で起動する必要があると気づきます。そこで、factory サービスを3つ同時に動かし、すべてがキューから注文を取り出して処理し、同じ共有の factory データベースに書き込む、といった構成にするかもしれません。
その場合、order データベースや RabbitMQ など、各コンポーネントの URL を一元管理するリポジトリが必要になります。コンテナが起動・停止するたびに URL やポートが変わっても新しく起動したサービスが参照先を見つけられるようにするためです。
こうしたサービスディスカバリを支える仕組みとして、etcd のようなコンテナ内のシンプルなキー・バリュー型ストアを使うこともできますし、Consul のようにより強力なものを使うこともできます。あるいは、Kubernetes のようなコンテナオーケストレーターを使う選択肢もあります。
サンプルアプリ
このガイドに付属する GitHub リポジトリでは、ケーススタディで扱ったサービスを動かす最小限のマイクロサービスアプリを用意しています。
▶️ リポジトリをクローンする、またはダウンロードして解凍し、手元のコンピュータに配置してください。
リポジトリには withSentry と withoutSentry の2つのフォルダがあります。このガイドでは監視のデモのために withSentry のアプリを実行しますが、監視機能を一切含まない、さらにシンプルなマイクロサービス設計を見たい場合は、withoutSentry のコードを確認できます。
以下は両フォルダで使用している設計の簡略図です。バックエンドの各コンポーネントは、docker-compose.yaml で構成された別々の Docker コンテナで動作します。構成要素は次のとおりです。
- Node.js サービスが3つ(3_web.ts、4_order.ts、5_factory.ts)
- MongoDB データベースが3つ(Docker Composeファイルの先頭付近にある msWebDb、msOrderDb、msFactoryDb)
- RabbitMQ Docker Compose ファイルの中央付近に記載されています。

アプリが Sentry Tracing を使うように設定する
アプリをダウンロードしたので、次はトレースを Sentry へ送信するように設定しましょう。
▶️ Sentry の Web インターフェースを開き、サイドバーから「Settings」→「Projects」に移動します。
▶️ このテストで使用するプロジェクトを選択します。利用できるのが実運用のプロジェクトしかない場合は、先にデモ用に Node.js プロジェクトを作成してから選択してください。
サイドバーの内容が切り替わり、プロジェクトの詳細が表示されます。
▶️ サイドバーで「Client Keys (DSN)」に移動し、DSNをコピーします。
▶️ withSentry のプロジェクトディレクトリで .env ファイルを開き、コピーした DSN を SENTRY_DSN 環境変数の値として入力します。
この設定により、アプリ内のすべてのサービスがあなたの Sentry プロジェクトを使用するようになります。Docker Compose は .env から SENTRY_DSN の値を読み取り、SENTRY_DSN 環境変数を持つコンテナへその値を渡します。
▶️ Sentry でサイドバーの一番下にある「Loader Script」に移動し、ページ上部に表示されているスクリプトをコピーします。
▶️ withSentry/index.html を開き、ファイルの上部(<head> の直下)付近にある script 行をコピーしたローダースクリプトに置き換えます。
この設定で、アプリのフロントエンドの Web ページがあなたの Sentry プロジェクトに紐づきます。さらに、たとえば Sentry へ送るトレースの割合を一部に絞るなど、アプリを追加で設定したい場合は Loader Script のドキュメントを参照してください。
アプリを実行する
設定は完了です。アプリを起動し、Sentry にトレースが届くことを確認できます。
▶️ withSentry フォルダでターミナル(コマンドプロンプト)を開き、次のコマンドを実行します。
docker compose up
別のターミナルで docker ps を実行すると、10秒〜数分ほどで、すべてのコンテナが healthy と表示されるはずです。Docker イメージや npm パッケージのダウンロードには時間がかかる場合があります。

注:コンテナ名は microservice の略である ms で始まります。これは他に実行しているコンテナと明確に区別するためです。
▶️ Web ブラウザで http://localhost:8006 を開き、アプリにアクセスします。
▶️ 広告ブロッカーやトラッカーブロッカーを無効にしてページを再読み込みし、Sentry が利用できる状態になっていることを確認してください。

Sentryのブロックを解除
ページを再読み込みするたびに Create order の行には新しい UUID が設定されますが、alice や 2 のように、自分で注文名を入力することもできます。
▶️ Submit をクリックして注文を開始します。
Check order の行に注文IDが設定され、Webサービスに対して1回チェックを行うだけで Order status が更新されることに気づくはずです。
▶️ Order status が約10秒後に finished に変わるまで、Check を繰り返しクリックします。

マイクロサービスのウェブサイト
ここまでで起きたことは次のとおりです。
- Web ページが web サービスを呼び出し、web データベースに注文が作成されました。
- web サービスはその注文IDを RabbitMQ 上のメッセージとして order サービスに送信しました。
- order サービスはそれを受け取り、保存し、factory サービスへ注文を渡しました。
- factory サービスは注文を受け取り、5〜10秒待ったのち、「商品が作成された」というメッセージを RabbitMQ へ送信しました。
- orderサービスはそのステータス更新を web サービスへ返しました。
- Check ボタンをクリックすると、web サービスに注文ステータスを問い合わせます。web サービスは web データベースを参照してステータスを返します。
この流れが Sentry 上で明確に表示されるか確認してみましょう。
▶️ Sentry のサイドバーで「Explore」→「Traces」に移動し、トレースページ上部でテスト用プロジェクトが選択されていることを確認します。
トレースが表示されている場合は、次の「トレーシングを理解する」セクションへ進んでください。
1分待ってもトレースが表示されない場合は、下記のトラブルシューティング手順に従ってアプリ設定の問題を確認してください。新しいSentryプロジェクトの場合は、まず Set up the Sentry SDK セクションの各ステップで Next をクリックして次の進み、最後に Take me to my trace をクリックしてください。
トラブルシューティング
このアプリケーションは、あなたのコンピュータ上で 8000〜8006 の6つの空きポートを必要とします。万一、他のアプリケーションがこれらのポートを使用している場合は、そのアプリケーションを停止してください。
▶️ 新しいターミナルを開き、以下のコードを実行してサービスのログを確認します。

出力は次のようになります。
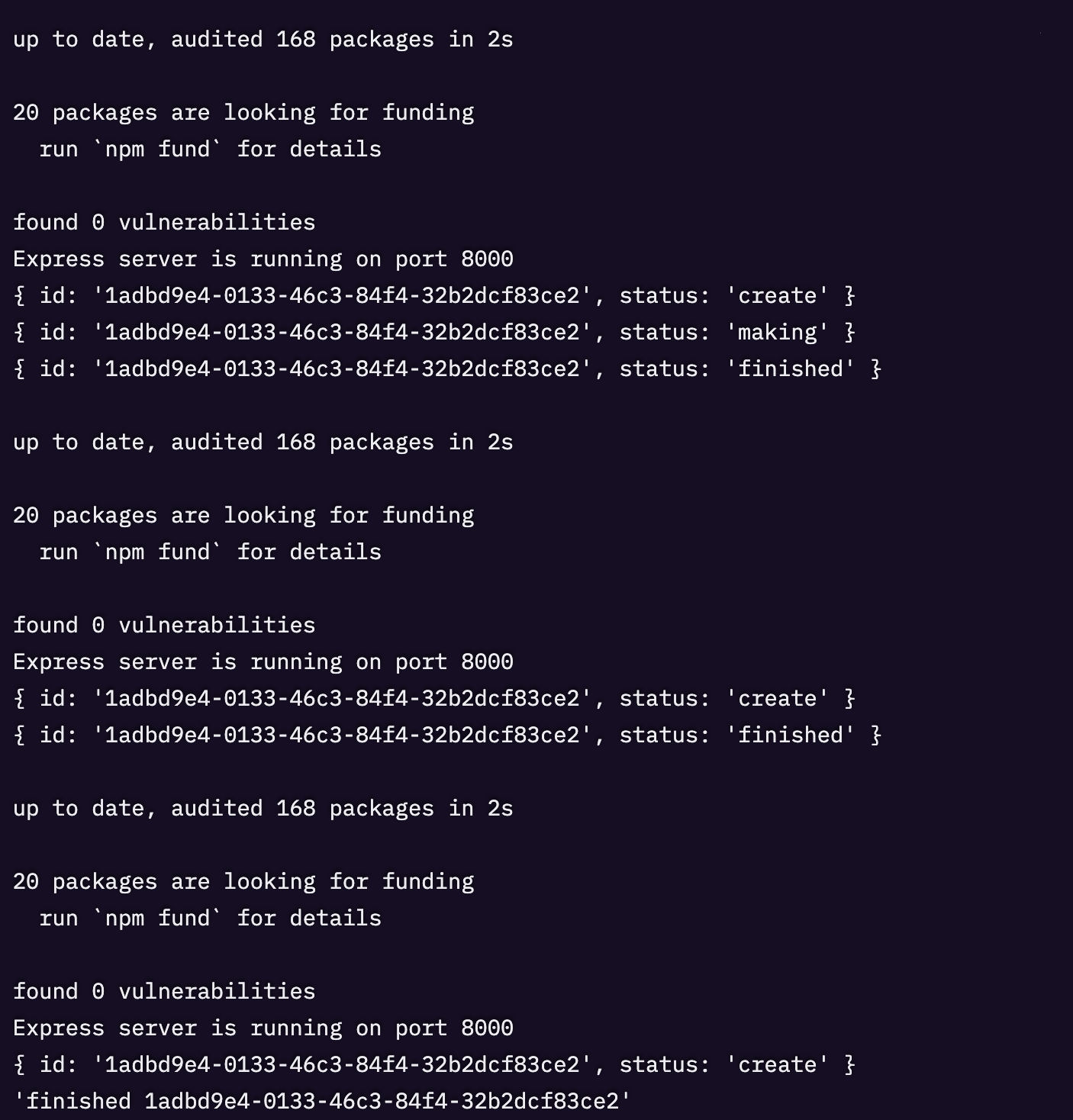
エラーが見つかった場合は Sentryでトレースを確認しようとする前に、まずそれらを修正してください。
最も起こりやすい問題は .env ファイルに設定したプロジェクトの DSN が、Sentry 側のものと一致していないことです。そうでなければ、npm がインターネットに接続できず、パッケージをダウンロードできなかった可能性が高いです。その場合は、ファイアウォールや VPN を一時的に無効化し、プロジェクトフォルダでDocker を次のコマンドで再起動してみてください。

また、以下のコマンドを使ってデータベースの内容を確認することもできます。
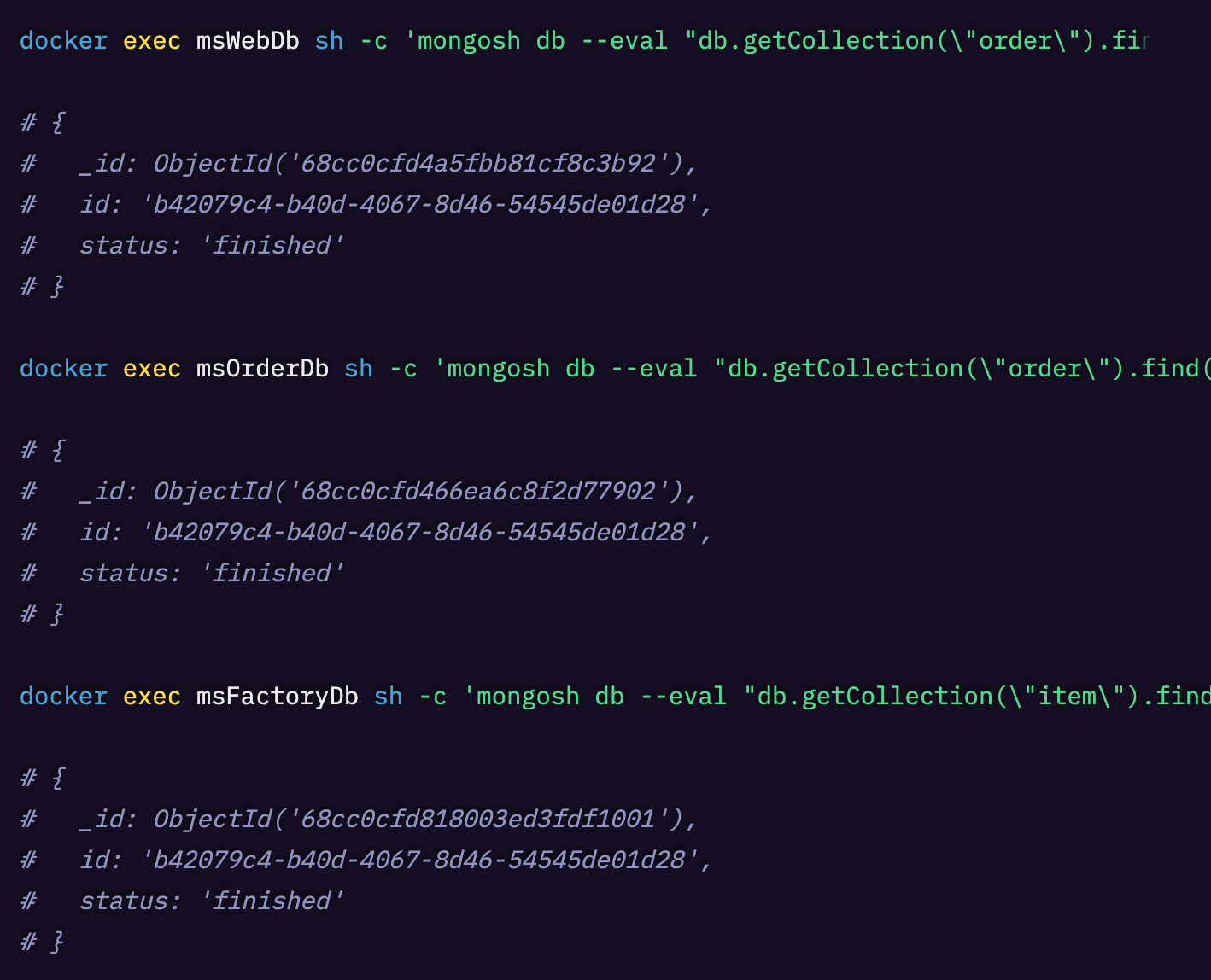

分散トレース
分散トレーシングの効果が出るのはまさにこの瞬間です。
すべてのサービス呼び出しが1か所にまとまって表示されます。Sentry はサービスが行う各呼び出しにトレース ID を付けて渡すため、Web サイトから factory まで、そして再び戻ってくるまでのサービス呼び出しとデータベース呼び出しの流れ(RabbitMQ のメッセージ経由も含む)を追跡できます。この流れはページ左側のコールスタックを上から下へ読んでいくことで確認できます。
Web ページの span には、ページの読み込みから個々のボタンクリックまでがすべて含まれています。RabbitMQ 自体は Sentry で計測されていませんが、それを呼び出すJavaScript は計測されているため、RabbitMQ へ送信されたメッセージと RabbitMQ から受信したメッセージをすべて確認できます。同様に、MongoDB 自体は Sentry で計測されていませんが、MongoDB への呼び出しは計測されています。
データベース呼び出しを見ると、パラメータが記録されていないことが分かります。
たとえば、次のようになります。

これは「クエリスクラビング(query scrubbing)」と呼ばれます。Sentry はこれを使って、クレジットカード番号やパスワードハッシュのような機密データが記録されないようにしています。正確なクエリの詳細が必要な場合は、代わりに Sentry Logs で取得できます。
では、このトレースは何の役に立つのでしょうか。
まず、システムが想定どおりに動いているかを示します。制御フローが正しいか、メッセージが重複していないか、障害やデータベース書き込みの抜け漏れがないか、といった点を確認できます。
ロジックが正しく見えるようになったら、次はパフォーマンスを見ます。注文全体にどれだけ時間がかかっているか。遅い、あるいはばらつきのあるリクエストがないか。どのサービスが原因なのか。
さらに、ユーザーから問い合わせがあったときには、その注文 ID に対応するトレースを見つけて、何が起きたのかを正確に確認できます。
上の例では、下部付近でインデントから外れるようにフローが戻っています。これは factory がキューへ新しいメッセージを送る前に、数秒待って商品を「製造」しているタイミングです。

実際のシステムは数秒で応答しません。更新は元のトレースが終わったずっと後に届くこともよくあります。それらを結び付ける方法は、共通の識別子を使うことです。
ここでは、その識別子が注文 ID です。注文 ID がサービス間の span に付与されているため、Sentry でそれを検索すれば、ライフサイクル全体を1か所で確認できます。
▶️ アプリの Web ページ上のテキストボックスから注文 ID をコピーし、下の例のように Sentry の Traces ページのフィルタへ貼り付けてください。(フィルタのテキストボックスに直接入力することはできません。まず orderId と入力し、表示される追加オプションをクリックする必要があります。)

注文IDをトレースする
右側にある Edit Table ボタンをクリックすると、フィルタ結果に表示する属性を、気になるものに合わせて追加できます。
Logs
この記事は分散トレーシングに焦点を当てていますが、Sentry は Sentry.captureException(e) を使ったエラーや例外の収集といった、一般的な監視タスクにも対応しています。
例外のスタックトレースにはサービス横断のコンテキストが含まれないため、エラーを送信する前に orderId のような識別子を付けておくことが重要です。その方法のひとつが、breadcrumb を使うことです。
breadcrumb は軽量なコンテキストで、ローカルに記録され、エラーなどのイベントが発生したときにだけ Sentry へ送信されます。たとえば、factory が商品の作成を開始したタイミングで、次のように追加できます。

その関数が後でエラーを投げて、それをキャプチャした場合、breadcrumb は Sentry 上でスタックトレースと並んで表示されます。
構造化ログも似ていますが、より強力です。単一のテキストメッセージではなく、キーと値のペアを記録するため、ダッシュボード上でのフィルタリングや検索がしやすくなります。breadcrumb と違い、構造化ログは即座に送信され、エラーに紐づくものでもありません。
このマイクロサービスの例では、こうした追加コンテキストを提供するために、トレースと併せてログを使用しています。
▶️ Sentryのサイドバーで Explore → Logs に移動します。

分散ログ
上のスクリーンショットでは、構造化ログに追加した2つの属性(orderId と service)がテーブルに含まれています。各サービスが RabbitMQ からメッセージを受信したタイミングでログを出していることが分かります。
この簡略化した例では、注文がシステム内を流れていく様子をどちらも表示するため、トレースとログは似ているように見えます。ただし、実際のアプリケーションでは役割が異なります。
トレースは実行がコンポーネント間をどのように移動するかを示します。
ログは自分のビジネスロジックの中で必要なコンテキストを自由に記録できます。特定のステップにログを追加したり、デバッグ中だけ一時的に調整したり、終わったら削除したりできます。
Sentry Logs は重大度レベル(trace、debug、info、warn、error、fatal)にも対応しているため、開発・テスト・本番の各環境で有用です。詳しくは、Node.js で Logs を設定するガイドを参照してください。
Sentry で分散アプリを監視する方法
ここまでで、Sentry 上で監視がどのように見えるかを確認できました。次は、それをあなたのアプリに追加していきましょう。このセクションの例は、マイクロサービスに限らず、あらゆる Node.js アプリケーションで使えます。Sentry の観点では違いはなく、同じ考え方は Python や .NET など他の言語でも当てはまります。変わるのは構文だけです。
Webページを監視する
設定セクションで index.html に追加したローダースクリプトの読み込みは、Web ページの自動監視を始めるのに必要なことはそれだけです。
内容は次のようなものでした([YOUR_ID] は忘れずに置き換えてください)。

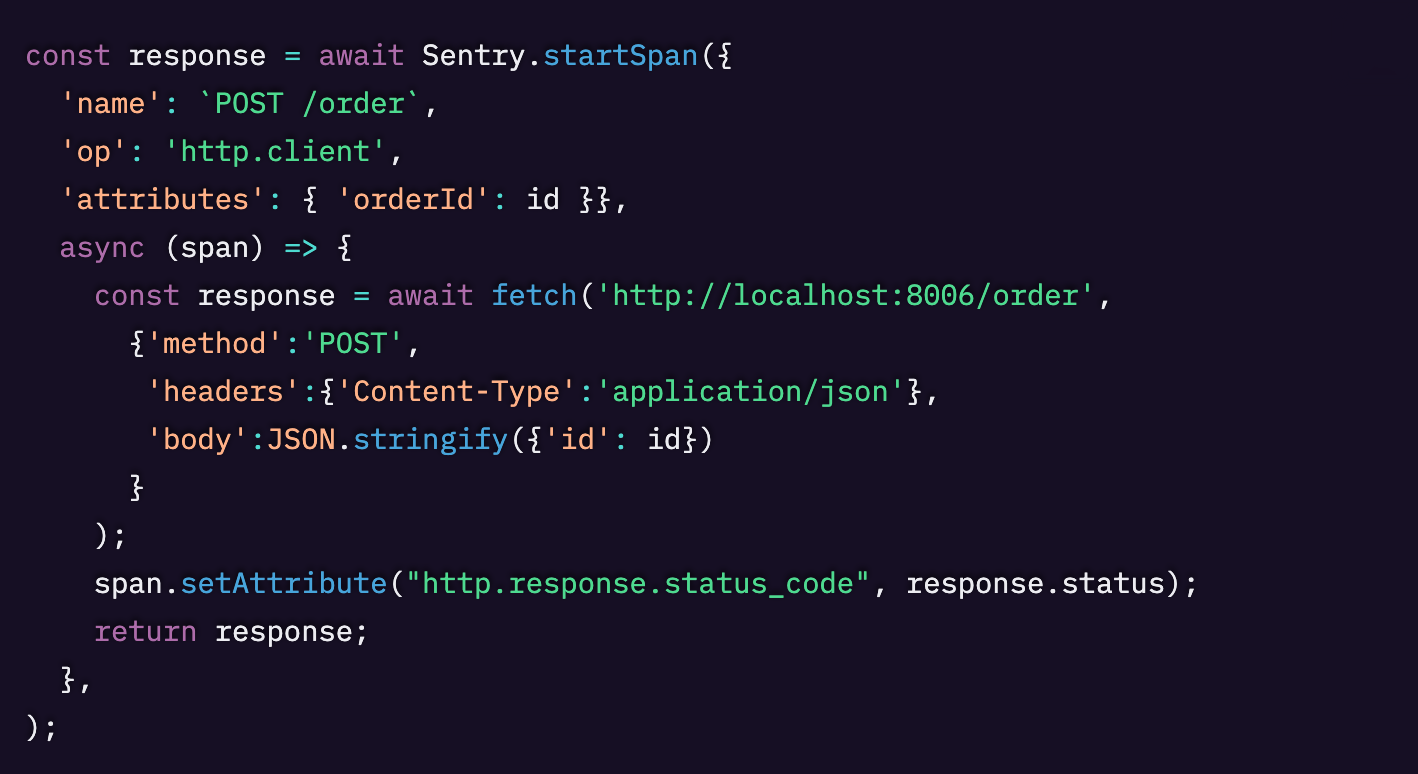
startSpan() 関数は、内部で行われる呼び出しを記録する span を手動で作成します。この例では、fetch(‘http://localhost:8006/order’) の呼び出しが記録されます。必須なのは name パラメータだけですが、このコードでは注文IDを属性として含めており、さらに呼び出しが完了した後に、レスポンスのステータスコードも属性として追加しています。
Web サービスを監視する
▶️ Web サービスを自動で計測するには、コードファイルの外側で Sentry の設定をインポートするだけで十分です。
このインポートは、次の Docker Compose ファイルのコマンドに示されています。

ファイル `1_sentry.ts` は Sentry の設定を行います。
内容は次のとおりです。
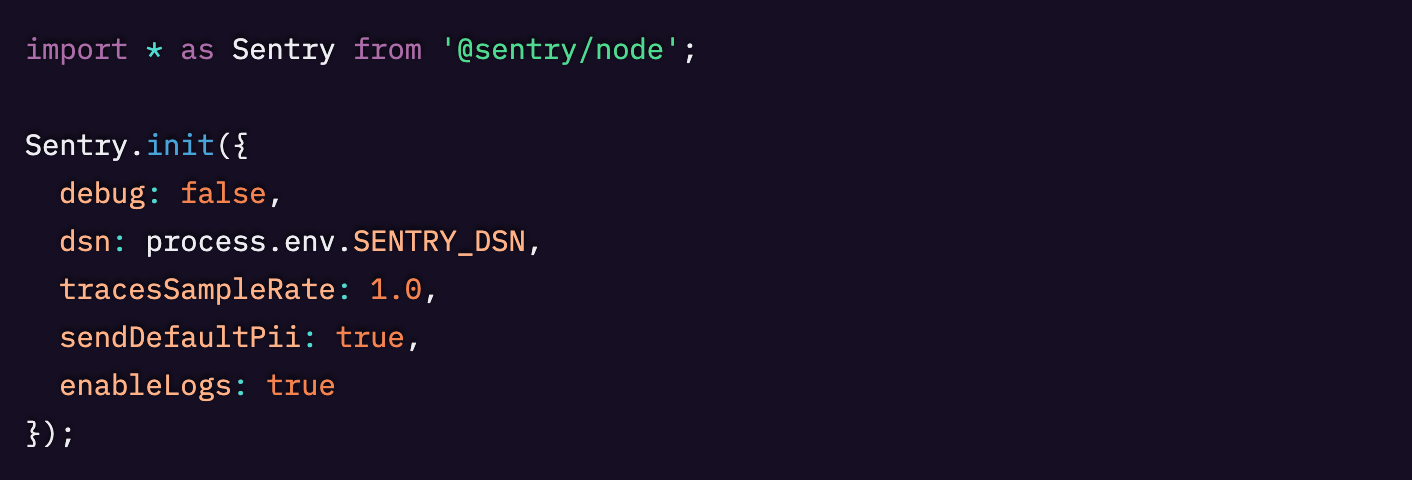
DSN がないと Sentry は動作しません。enableLogs がないと、ログは Sentry へ送信されません。
Sentry は MongoDB や RabbitMQ を含むいくつかのインテグレーション(監視プラグイン)をデフォルトで自動有効化します。
▶️ アプリが他のツールを使っている場合は、インテグレーションのドキュメントを確認し、有効化の方法を学んでください。
サービスを Sentry で自動監視するのに必要なのは、基本的にこの単一の設定ファイルだけです。ただし、orderId のようなカスタム属性をサービス横断で付与したり、Logs を使ったりする場合は、コード内でも Sentry ライブラリをインポートし、いくつか手動の計測も追加する必要があります。
▶️ 次の1行で Sentry をインポートしてください。

▶️ ログエントリを送信するには、次の1行を使用できます。

この呼び出しでは、テキストメッセージと、JSON として送信される2つの属性が含まれています。
▶️ span に属性を追加するには、次のコードを使用します。

この行は、Sentry の自動計測によって作成された span に属性を追加します。
Sentry の Web サイトでトレース内の span をすべて確認すると、order ID 属性を持たない span があることに気づくかもしれません。ID 属性が必要なのに、Sentry が自動的に作成した span がなく、付与先がない場合は Web サイト側のコードが行っているのと同様に`startSpan()` を使って手動で span を作成する必要があります。
マイクロサービスと分散システムを監視するためのヒント
要点は次のとおりです。
- Sentry はほとんどの操作について、手動の計測なしで自動的に span を作成します。
- Logs やカスタム属性を追加するには、それらを明示的に計測する必要があります。
- 組み込みのインテグレーションがないツール(いくつかのメッセージキューやデータベースなど)では、インテグレーションを有効化するか、手動の計測を追加する必要があります。
- 分散システムには単一のコールスタックがないため、非同期処理をサービス間で結び付けるには、orderId のような共通の識別子が必要です。UUID は有効です。後から検索しやすい形であることが重要です。
サービスが独立すると、監視の設計も変わります。本ガイドではすべてのトレースを単一のSentryプロジェクトに送っていますが、実務ではアラート、データ、ワークフローを各チームが管理できるように、プロジェクトを分割することがよくあります。しかしこれにより責務の分離は明確になりますが、運用は複雑になります。とはいえ、必要に応じて管理者はプロジェクト横断でトレースを調査することができます。
その独立性があるため、チーム間で共有するルール(共通の規約)にも合意が必要になります。設定の集中管理と一貫したメッセージ形式があると、障害時にサービスをまたいでリクエストを追うのが格段に容易になります。
最後に、マイクロサービスはトラフィックが非常に多くなります。まずはトレースのサンプリング率を低め(目安として10%程度)にして、情報量に押しつぶされずにシステムの挙動を把握してください。アプリケーションがスケールするにつれて、サービス負荷やリクエストのレイテンシを監視し、スケールアップのタイミングを判断できるようにしておきましょう。
Original Page: Monitoring microservices and distributed systems with Sentry
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。