Article by: Tillman Elser, Josh Ferge
Sentry は Issue Grouping(イシューグルーピング) を使用して、同一のエラーを集約し、重複するイシューの作成やアラートの送信を防止しています。
しかしこれまでにユーザーから最も多く寄せられていた不満の一つは、既存のアルゴリズムでは一部のケースで類似エラーが十分にまとめられず、Sentry が別々のイシューやアラートを生成してしまうことでした。これにより、開発者にとって不要な混乱、あるいは少なくとも煩わしさが生じていたのです。
この課題に対応するため、私たちは過去最大規模のイシューグルーピングアルゴリズムの改良を行いました。新しいAI搭載のアプローチでは、Transformer ベースのテキスト埋め込みモデルを使用し、新規イシューの生成数を40%削減しつつ、エンドツーエンドの処理レイテンシーを100ミリ秒未満に維持しています。
本記事では、このAIを活用したイシューグルーピングの開発・テスト・デプロイのプロセスについてご紹介します。
なぜ重複イシューが発生するのか
Sentryの主要な価値は、ログを延々と読むことなく、必要な情報に素早くアクセスできる点にあります。新たな問題が発生すると、イシューフィード、メール、メッセージングプラットフォームなどを通じて開発者に通知されます。この一連のプロセスの鍵を握るのが、グルーピングアルゴリズムです。
経験豊富な開発者であれば、2つのスタックトレースを比較し、それらが同一の問題かどうかを判断するのはそれほど難しくありません。しかし、この判断プロセスを堅牢なヒューリスティック(経験則)として実装するのは容易ではありません。
たとえば、Reactアプリケーションでは、同じ「Invalid prop」エラーが異なるスタックフレームの順序で出現することがあります。あるときは validateProp(Select.js:42) に続いて Anonymous Component(App.js:123) が現れたり、逆の順番になったりすることもあります。同様に、Python では一見同じ KeyError が、コードのリファクタリングによりわずかに異なる行番号(たとえば line 145 と line 147)で発生することもあります。
さらに、非同期処理(async) はより一層複雑になります。たとえば Python の async 関数内で ValueError が発生した場合、それが asyncio/tasks.py を経由するか asyncio/runners.py を経由するかで、同じエラーが異なる実行パスを通って表面化することがあります。
私たちのグルーピングアルゴリズムは、これらのバリエーションを同一の根本原因として扱いつつ、明確に異なるエラーは正しく区別できなければなりません。しかも、Sentry は高速かつ効率的である必要があります。イベントの取り込み速度の低下や処理コストの増大は許容されません。
従来のグルーピング手法の問題点
従来のグルーピングアルゴリズムは、段階的に広いマッチング戦略を適用しながら、各エラーに対してユニークなフィンガープリント(指紋)を生成することで動作します。最も精度の高い手法であるスタックトレースの分析から始まり、アルゴリズムは各フレームを検査します。その際、アプリケーションコードとサードパーティライブラリを慎重に区別し、さらにプラットフォーム固有のルールに従って正規化を行います。
たとえば、Python のトレースバックと、難読化された JavaScript のスタックトレースはそれぞれ異なる方法で処理されます。スタックトレースが使用できない、あるいは情報が不十分な場合には、システムは例外タイプやその値の検査へとフォールバックし、最終的にはエラーメッセージを正規化したバージョンを使用します。
最終的な出力はそのエラーを表す「フィンガープリント」あるいは「ハッシュ」です。
理想的には、同じスタックトレースにより引き起こされた別のエラーが送られてきた場合、同一のフィンガープリントが生成され、それらが同じイシューとしてグループ化されることになります。
このような階層的アプローチは、実環境での長年の使用を通じて洗練されてきたものであり、関連性の高いエラーを適切にまとめつつ、性質の異なる問題は明確に区別することを目的としています。
グルーピング改善に向けた初期の取り組み
私たちの主な目標は、イシューに対してより原理的な類似度の指標(similarity metric)を導入することでした。そうすることで、スタックトレースを事前処理するためにますます複雑化するヒューリスティックに依存することを避け、十分に類似したスタックトレースを単純にマージできるようになると考えました。
この方針に基づき、私たちはテキスト類似度の指標、特に レーベンシュタイン距離(Levenshtein distance) の検討を始めました。これはある文字列を別の文字列に変換するために必要な、1文字単位の編集操作の最小回数を測定する手法です。このアプローチは、2つのスタックトレースがどの程度異なるかを直感的かつ正確に数値的に評価できる点で有用でした。しかし大規模なデータに対してこの比較を適用するには、非現実的で実用的とは言えませんでした。
このパフォーマンス上の課題に対処するため、私たちは Locality Sensitive Hashing(LSH) を評価しました。LSH は編集距離を正確に計算する代わりに、テキストをベクトル空間に投影し、類似したテキスト同士が同一、または近いハッシュバケットに入るようにする手法です。スタックトレースに対しては、n-gram(n文字の連続列) や shingle(重なり合うフレームのシーケンス) に分割し、MinHash を用いて集合類似度を近似することで実現しました。この方法により、新たなエラーごとにコーパス全体を比較せずとも、類似候補を効率よく見つけることが可能になりました。
しかし私たちは、すぐに重要な限界に気づきました。テキスト類似度(正確な計算でも LSH による近似でも)では、実際のエラーの類似度を適切に表現できない場合があるのです。たとえば、文字列として非常によく似たスタックトレースであっても、ルート例外のタイプや発生フレームが異なれば、根本的には異なるエラー条件を示している可能性があります。逆に、編集距離的には大きく異なって見えるトレースでも、実際には同じ根本的なエラーであり、単に変数名や行番号がコード変更によって変わっているだけということもあります。
私たちに必要だったのは、テキスト的な類似性ではなく、エラーの意味的構造(セマンティクス)を捉えることができるアプローチでした。
AI を活用したソリューションへの到達
私たちの最終的なアーキテクチャは、現代的な RAG(Retrieval-Augmented Generation)システムを構築している人にとってはおなじみのものかもしれません。その中核には、スタックトレースをベクトルに変換し、それぞれのエラーの意味的本質(semantic essence)を捉えるようにファインチューニングされた、トランスフォーマーベースのテキスト埋め込みモデルがあります。
このアプローチは、単純な編集距離のような手法よりも優れています。なぜなら、トランスフォーマーのアテンションメカニズムによって、行番号の変動などのノイズを除外し、本当に意味のある類似性のシグナルに集中できるからです。Sentry はオープンソースであると同時に Postgres のヘビーユーザーでもあるため、優れた pgvector 拡張をベクトル検索(HNSW インデックスを使用)およびストレージに用いるのは自然な選択でした。
比較的シンプルなアーキテクチャ
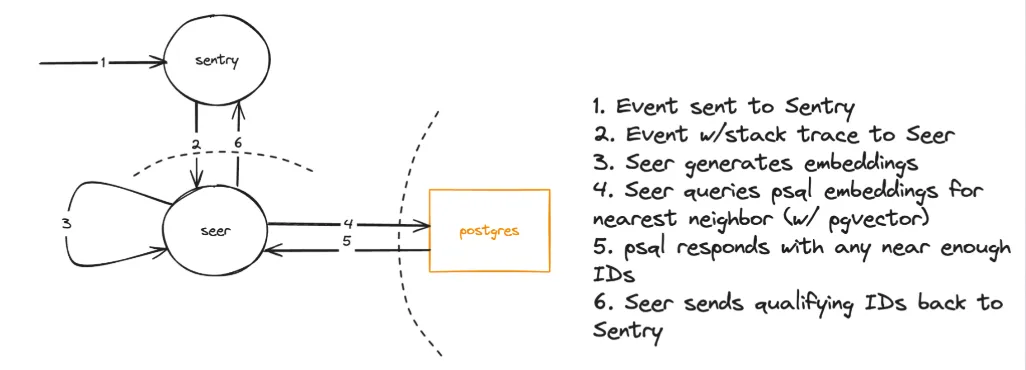
私たちの既存のコスト効率の高いフィンガープリントアルゴリズムが新しいハッシュ(既存のグルーピングシステムで生成されたもの)を検出すると、エラーデータは Seer(私たちの AI/ML サービス)に送信されます。Seer はベクトル埋め込み(embedding)を生成し、データベース内の既存の埋め込みと照合します。
一致が見つかれば、Sentry はその新しいハッシュを既存のイシューとマージします。ほとんどのエラーは既存の古典的なフィンガープリントによって容易に識別されるため、高コストなベクトル埋め込みは、実際に重複排除が必要なケースに限定して発生します。
評価
今回の変更の品質評価において、私たちは一切の手抜きをしませんでした。
社内で婉曲的に「エスケープルーム(Escape Rooms)」と呼ばれるようになった取り組みでは(=ラベリングが終わるまで部屋を出られないという意味合い)、AI 搭載のイシューグルーピングが従来のロジックとは異なる判断を下した事例を、数千件にわたってエンジニアたちが手作業でラベリングしました。

私たちの目標は、すべてのユーザーにとってグルーピングの品質を向上させることであり、同時に誰にとっても悪化させないことでした。この前提に基づき、私たちは類似度スコアに対して非常に保守的な閾値(しきい値)を設定しました。この閾値は、人間の評価者が「2つのスタックトレースは意味的に同一である」と判断するケースとほぼ完全に一致するよう設計されています。
同時に「過剰修正(overcorrecting)」、つまり、無関係なイシュー同士を過度にまとめてしまう事態が発生しないようにも配慮しました。この保守的な類似度の閾値選定のおかげで、内部テスト中に誤って異なるイシューをグルーピングしてしまう「偽陽性」の発生率はほぼゼロとなりました。また誤って新しいイシューが作成される件数の大幅な削減も実現できました。
また、私たちはアルゴリズムの品質向上やコスト削減を目的とした複数の戦略も評価しました。最初の最適化は 埋め込み(embedding)の量子化(quantization) に着目したもので、float32(単精度)による埋め込み表現を、float16、int8、バイナリ表現などと比較しました。量子化によってベクトルサイズを最大で 32 倍小さくするなど、大幅なストレージ節約や距離計算の高速化が得られましたが、精度の低下が確認されたため、最終的には完全な精度の埋め込み(float32)を維持する判断をしました。
さらに、近似最近傍検索(ANN:Approximate Nearest Neighbor)およびその基盤となるHNSWインデックスの最適化についても複数の方針を検討しました。たとえば、候補の再ランキング対象数(top-1〜top-100)を変化させながら、正確なコサイン類似度による正確な再ランキングを行う実験を実施しました。実運用環境での検証の結果、top-100再ランキングは、レイテンシーへの影響をほぼゼロに抑えたまま、リコール(再現率)を約1%向上させることが確認されました。
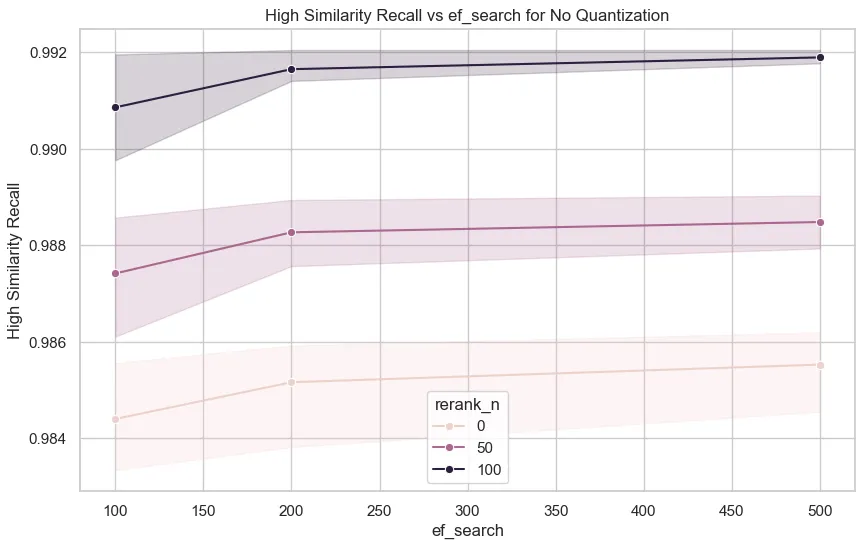
pgvector クエリ実装によって、再ランキングの上限を top-100 に増やしてもパフォーマンスへの影響が少ない理由が明らかになりました。私たちは候補検索クエリにおいて k=100 を設定していますが、2つの距離しきい値を適用しています。1つは 初期の HNSW ベースのフィルタリングに用いる、より寛容な hnsw_distance、もう1つは 最終的なマッチングのための、より厳格な距離しきい値です。
このクエリはまず、HNSW インデックスを使って、寛容なしきい値の範囲内にある候補を効率的にフィルタリングし、その後、厳密なコサイン距離計算を、距離が小さい順に最大 100 件の候補に対して適用します。実際には、このより厳しい距離しきい値のおかげで、再ランキングの際に処理する候補数は通常 100 件よりはるかに少なくなっています。
![]()
AI 搭載のイシューグルーピングを本番環境へ導入する
CPU vs GPU 推論
モデルが比較的小型(1億6100万パラメータ)であることから、コストを抑えつつ CPU でも十分なパフォーマンスが得られるかどうかを評価したいと考えました。locust を用いて、NVIDIA L4 GPU を使用した構成と、CPU のみのインスタンスの構成でさまざまなテストを実施しました。CPU 推論のチューニングに関しては、Roblox によるこのブログ記事が非常に参考になります。
最終的に GPU は CPU 推論と同等のコストでありながら、約 4 倍高速であることがわかりました。バッチ処理を用いればさらに高速化できる可能性もありますが、それを既存の取り込みパイプラインと統合するのは困難であると判断しました。現在の実装では、gunicorn と Flask を使用しており、スレッドを用いて並行性を高めています。
gunicorn のワーカー数を増やすことで GPU の使用率は向上しましたが、各ワーカーが GPU メモリ内にモデルのコピーを個別に読み込むため、メモリ制約が発生し、スケールアップが困難になるという課題が浮上しました。この課題については、TorchServeのようなフレームワークへの移行や、ワーカー間でモデルを共有できる構成への変更によって解決できる可能性があると考えています。(こちらの記事が参考になります)
pgvector の最適化
以下は、pgvector の運用にあたって実施した調整と考慮事項です。
HNSW インデックス
HNSW インデックスは、メモリ上に格納した場合に最も高い性能を発揮します。そのため、データベースのサイズを適切に見積もるために、以下の式を用いて 1 ベクトルあたりのメモリ使用量を推定しました。
1ベクトルあたりのメモリ = d × 4 + M × 2 × 4
ここで
- d はインデックスされるベクトルの次元数
- M は構築されるグラフにおけるノードあたりのエッジ数(今回は 16 に設定)
この式はおおよその方向性として正確であることが分かりましたが、実際の本番環境でのメモリ使用量は予想よりも多くなりました。
ハッシュパーティショニング
パフォーマンスを向上させるために、project_id に基づくハッシュパーティショニングを適用しました。この最適化は重要でした。というのも、HNSW インデックスはテーブル内のすべてのパーティションで共有される必要があるためです。この最適化により、クエリのレイテンシが改善され、リコールも向上しました。
実環境での結果 ー イシューとアラートが 40% 減少
これらの変更は、過去数か月にわたって段階的に展開されました。まずプロジェクトごとに既存のイシューを再処理(バックフィル)し、その後に新規のイベント取り込みを有効化しました。
全体として、ほとんどのプラットフォームおよびプロジェクトにおいて、新規イシューの作成数が約 40% 減少したことを確認しています。これは Sentry のユーザーが以前と比べて 40% 少ないイシュー(およびアラート)を受け取ることになることを意味し、気が散る機会が減り、より集中できる時間が増えることに繋がります。
AI によるイシューグルーピングは、すべての Sentry ユーザーに対してデフォルトで有効化されており、追加費用はかかりません。
皆さんの声をぜひお聞かせください!新しいイシューグルーピングに関するご意見・ご感想・ご提案などがありましたら、Sentry の Discord でお気軽にご連絡ください。
Original Page: Using a transformer–based text embeddings model to reduce Sentry alerts by 40% and cut through noise
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。