
Article by: Lazar Nikolov 、Ben Coe
MVP(Minimum Viable Product)と本番環境に耐えるアプリアプリを分ける要素は、仕上げ、最終調整、そしてパレートの法則で言うところの「最後の20%」の作業です。多くのバグやエッジケース、パフォーマンス問題は、リリース後にユーザーの殺到でアプリケーションに大きな負荷がかかったときに表面化します。この記事を読んでいるあなたは、おそらく80%地点にいて、残りを片付ける準備ができているはずです。
この記事では、大規模データセットをスケール環境でページネーションする際に、どこで問題が起こり得るのか、そしてデータベースのインデックスが結果をどう左右するのかを見ていきます。
本番の洗礼(ローンチ後の現実)
テスト中はすべて順調でしたが、しばらくするとページの読み込みに時間がかかるようになりました。
このような状況に備えて、Sentry をローンチ前にセットアップしておくことをおすすめします。カスタムのインストゥルメンテーションを何もしなくても、データベースクエリが遅くなったときに Sentry が知らせてくれます。
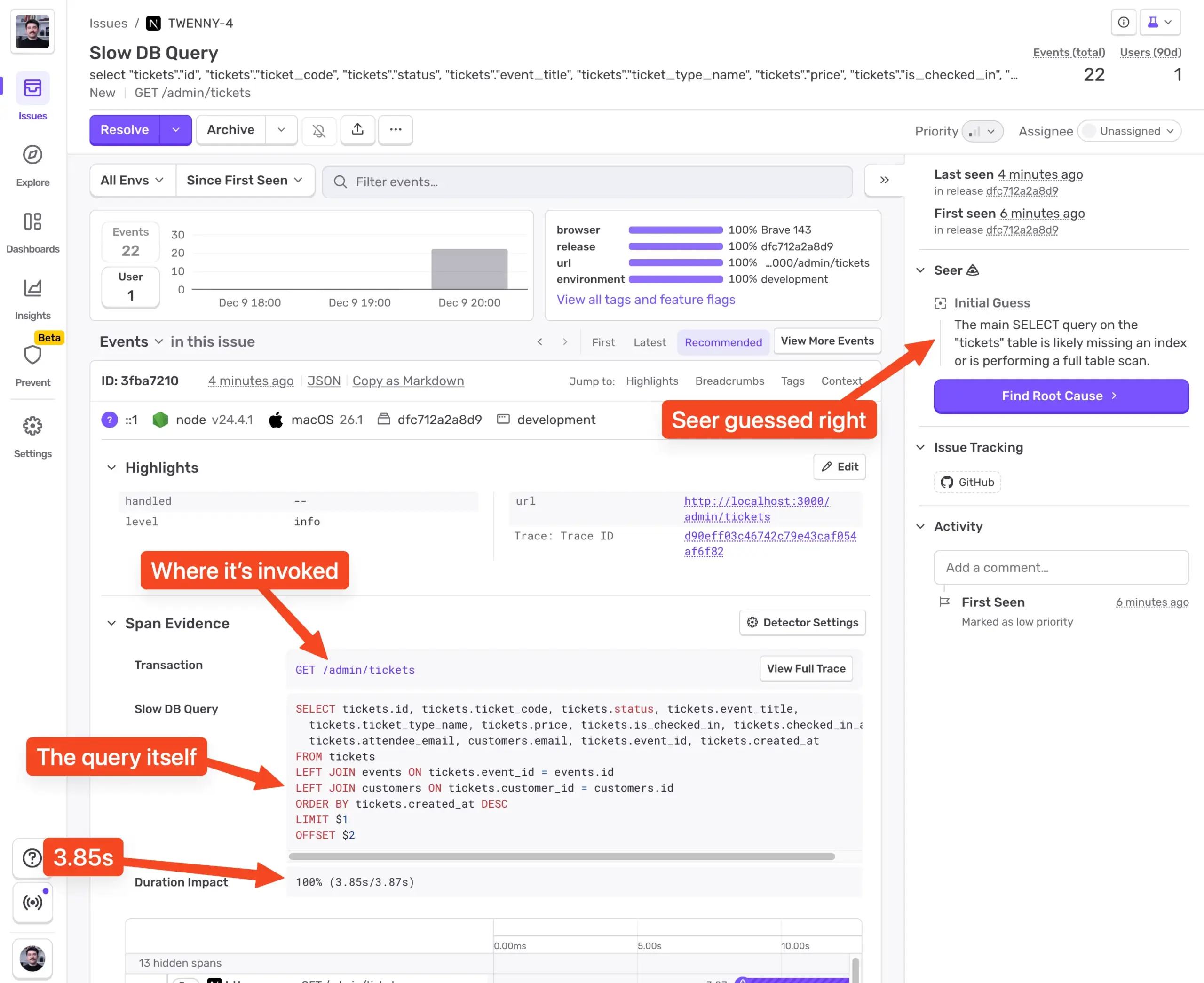
スクリーンショットには、Sentry での Slow DB Query の問題が表示されています。Drizzle ORM と node-postgres を使用したおかげで、Sentry は自動的にすべてのデータベースクエリを計測してくれました。このテレメトリデータによって、Sentry は遅いデータベースクエリを検出して表示できます。
少しスクロールすると、リクエスト情報が表示されます。

ここから分かることは次のとおりです。
- クエリは GET /admin/tickets リクエスト内で実行されています。
- OFFSET を含むため、オフセットベースのページネーションです。
- 実行されたのは 321 ページです。
- 実行時間は3.85秒でした。
- Seer はインデックス不足の可能性が高いと推測しています。
では、実際にインデックスが不足しているのか確認しましょう。
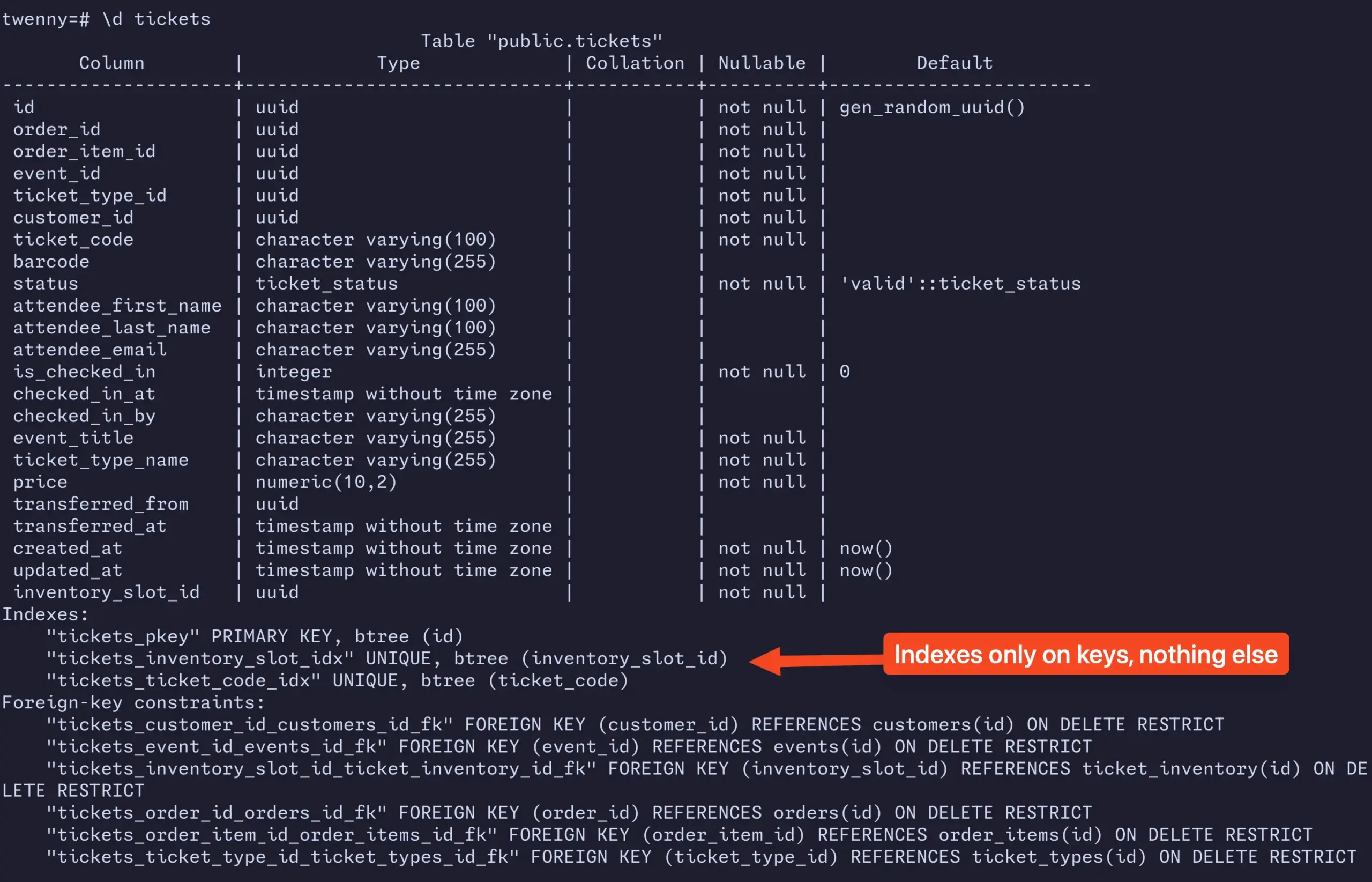
Seer の言った通りでした!大規模なデータセット、データベースインデックスの不足、そしてオフセットベースのページネーションの組み合わせがこの問題を増幅させています。
データベースにインデックスがなく、かつページネーションがオフセットベースのため、今回のように321ページのような高いページ番号に移動すると、データベースは 321 × page_size 行 をスキャンする必要があります。これが速度低下の原因です。
解決策(インデックスとカーソル)
この問題は、ページネーションをオフセットベースからカーソルベースへリファクタリングすることで解決できます。そのためには、データベースインデックスの追加も必要になります。
データベースインデックス
データベースインデックスは、テーブル全体をスキャンしなくても行を見つけられるようにする検索用の構造です。データを1行ずつたどる代わりに、エンジンが素早く参照できる「並べ替えられたマップ」だと考えると分かりやすいでしょう。
ただし代償があります。追加のディスク容量(実際はそれほど大きくありません)と書き込みコスト(書き込みのたびにインデックスも更新する必要があります)が増えますが、読み取りは劇的に速くなります。特にスケールしてくると、その差が顕著になります。
カーソルベースのページネーション
オフセットベースのページネーションでは、エンジンが毎回N行をスキャンしてスキップする必要があり、N が増えるにつれて遅くなります。
一方で、カーソルベースのページネーションは、前回取得した行の安定した値(「カーソル」)を使って次のページを取得するため、データベースは前回の続きの位置へ直接ジャンプできます。カーソルは通常、created_at や id、もしくはそれらの組み合わせなどのインデックスが付いた列が使われます。
実運用でのパフォーマンスと安定性という点で、は、カーソルベースのページネーションの圧勝です。
修正の適用
created_at と id を組み合わせた複合インデックスを作成しましょう。

書き込みロックを避けるために CONCURRENTLY を追加し、マイグレーションの冗長性を維持するために IF NOT EXISTS を指定します。
次に、カーソルから派生した id と created_at を使用して次のページを取得するために SQL を修正しましょう。
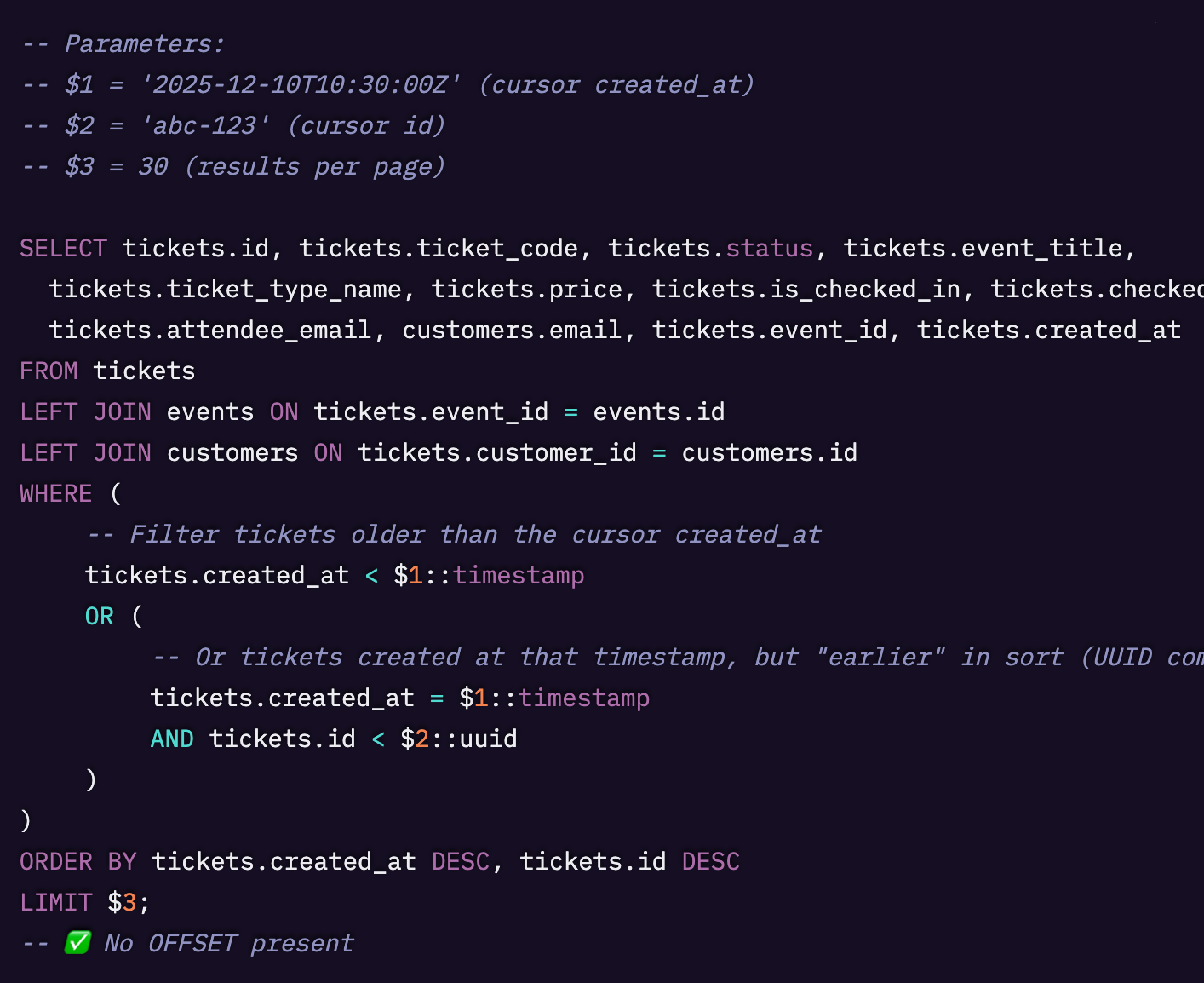
ページネーションを行う際にカーソルを計算して渡す必要があるため、URL は ?page=321 から ?cursor={nextCursor}&prevCursor={prevCursor} になります。
バックエンドは nextCursor を解析し、created_at と id を抽出し、上記の SQL で見られるような WHERE 句を適切に構築します。prevCursor は前のページに戻るためのものです。
検証(実行時間の低下を確認)
変更を適用して数分後、結果を確認します。
Sentry の Insights > Backend > Queriesに進みます。「+」ボタンをクリックしてフィルターを追加し、Spans > sentry.normalized_description を選択して追加します。それから、クエリの開始部分を含めるように修正します。SELECT … FROM tickets LEFT JOIN
このフィルターは、古いオフセットベースのクエリと新しいクエリの両方をキャプチャします。これにより、以下のチャートが更新され、「Average Duration」チャートを見ると、修正をデプロイしたタイミングを簡単に見つけられるはずです。
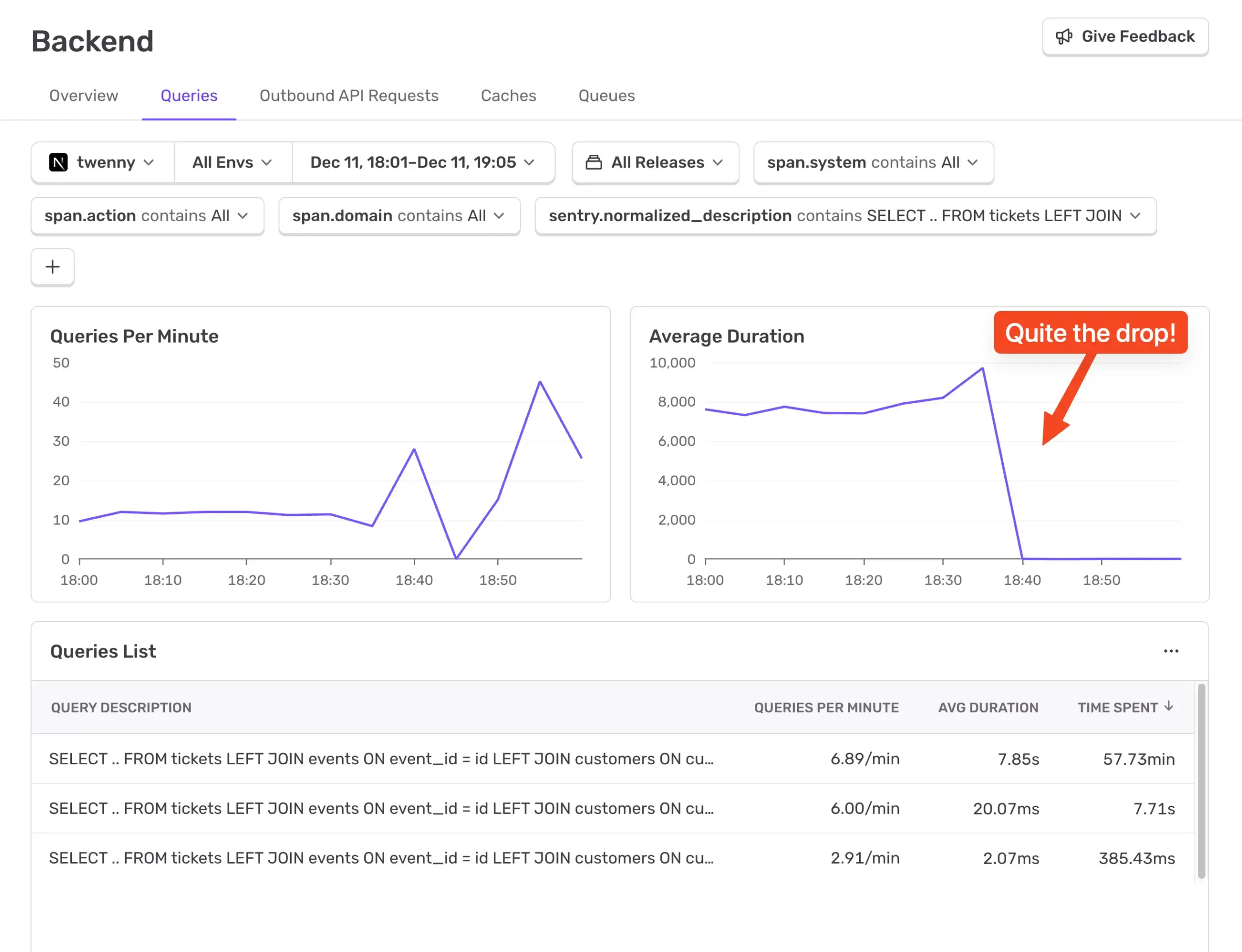
簡単に見つけられますね。そして、チャートはゼロに戻るわけではありません。約8秒から約13ミリ秒に下がりました。これはローカルでの実行ですが、本番環境でも大幅に高速化されるはずです。
これが、データベースインデックスを使用し、ページネーションをオフセットベースからカーソルベースにリファクタリングした効果です。ページに移動するたびに、データベースが毎回何千行、何百万行もの行をスキャンする必要がなくなります。
インデックスにより、「歩いて」移動するのではなく、特定の行に直接ジャンプできるようになります。そしてカーソルがどの行にジャンプすべきかを指示します。効率的ですね!
キーポイント(本番環境で実際に求められること)
これは特別な最適化ではありません。特殊なデータ構造も、キャッシュレイヤーも、AIもありません。テストデータが消え、現実が押し寄せたときにデータベースがどう動くかを踏まえて、基本に忠実に対応しただけです。
オフセットベースのページネーションとインデックス不足の組み合わせは、トラフィックが増えて初めて気づく「見えない税金」です。請求書は遅れて届き、あっという間に積み重なり、そのままユーザー体験に影響を与えます。カーソルベースのページネーションに適切なインデックスを付けると、コストの前提が根本から変わります。予測可能で、安定していて、良い意味での「退屈」になるのです。
重要なのは、クエリが秒からミリ秒になったことではありません。問題はパフォーマンス曲線の形状が変化することにあります。オフセットによるページネーションは、データが増加するにつれて線形的に劣化します。一方、カーソルベースのページネーションは平坦なままです。システムが成長に耐えるためには、このような平坦な曲線が必要です。
Sentry の役割は単に「遅いクエリを見つける」ことではありません。理論と実際の間にあるフィードバックループを閉じることです。変更を加え、デプロイし、システムが自分の理解どおりにシステムが動いているかを即座に確認します。このケースでは、データベースが勢いよくうなずいてくれました。
本番環境への準備を整えるには、こうした細かい部分が重要です。
インデックス、アクセスパターン、測定… 派手ではありませんが、結果を左右します。MVP はアイデアを証明しますが、本番システムは規律を証明します。
参考資料と関連リンク
このトピックに関する詳細は、データベースクエリの監視についてのドキュメントや、バックエンドパフォーマンスインサイトモジュールをご覧ください。さらに、N+1のデータベースクエリ問題を解消する方法について解説したブログもあわせてご覧ください。
Sentry を初めてご利用の方は、インタラクティブな Sentry Sandbox をお試しいただくか、無料登録を行ってください。質問があれば気軽に Discord にご参加ください。
Original Page: Paginating large datasets in production: Why OFFSET fails and cursors win
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。

