Article by: Rahul Chhabria
ステージ 1:本番前
(別名:「プロンプト墓場」)
今、プロトタイプを作っている段階だとします。ノートブック、ベクターストア、OpenAI API キー、そして夢もある。必要なのはダッシュボードではなく、壊れたプロンプトを必死に救い出すためのログです。
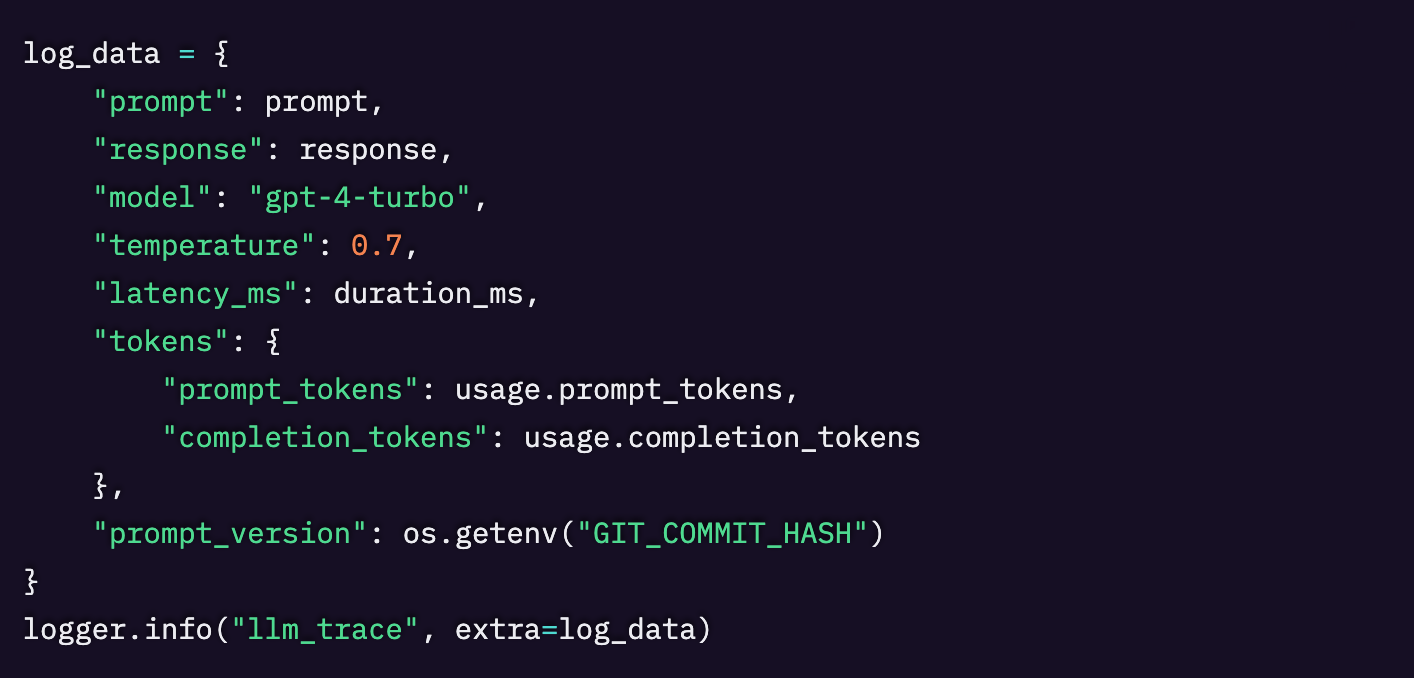
何をログに残すべきか
この段階でデバッグしているのは、ユーザーというより自分自身です。なので、以下をログに残しましょう。
- プロンプト全文とレスポンス全文
- モデル名、temperature、function schema のバージョン
- トークン使用量とレイテンシ
- プロンプトのバージョンを特定できる情報(何でもいいので)
必要なのはちゃんとしたトレーシング
これは「モデルに何を送ったか」の話ではありません。「ユーザーのクリックから、炎上するアウトプットが出るまでに何が起きたか」の話です。

無料でもしっかり役立つもの
- フロントエンドとバックエンドを横断してトレース ID を付ける
- OpenTelemetry か Sentry でリクエストの流れを追えるようにする
- リトライ回数とトークン使用量を追跡する
- レイテンシのスパイクとエラー率にアラートを設定する
ユーザーが何を見たのか、モデルが何を見たのか、そして途中で何が変わったのか。それが追えないなら、オブザーバビリティはできていません。やっているのは考古学です。
トレーシングがないと起こること
- ベクターストア障害中、リトライループが静かにトークンを燃やし続ける
- モデルが想定外のプレフィックスを付けて、UI が壊れる
- モデル変更の影響で Retrieval が動かなくなり、Twitter で初めて気づく
- レイテンシが 600ms 跳ねても、原因が誰にも分からない
見つけられないものは直せません。特にそれが JSON の塊の中で base64 に包まれているなら、なおさらです。

イベント:ワークショップ:Seer・MCP・Agent Monitoring で学ぶ Sentry AI デバッグ
WATCH VIDEO

最後にもうひとつ
監視がモデル呼び出しで止まっているなら、それは監視ではなく、ただ願っているだけです。
Sentry はアプリ全体を横断したリクエストトレースを提供します。ユーザーのクリックから、ツールチェーン、ベクターストア、モデル呼び出しを経て、アウトプットに戻るまでを追うことができます。さらに、エージェントのプラン内でツール呼び出しが失敗した理由まで、ログから文脈を再構築して、午後を全て費やすことなく確認することができます。
だから、推測はやめて、把握しましょう。そして、何が原因で壊れたのか忘れる前にプロンプトを必ずログに残してください。
詳しくはドキュメントをご覧ください。Discord で議論に参加することもできます。もしSentry が初めてなら、無料で始めることができます。
Original Page: What You Actually Need to Monitor AI Systems in Production
IchizokuはSentryと提携し、日本でSentry製品の導入支援、テクニカルサポート、ベストプラクティスの共有を行なっています。Ichizokuが提供するSentryの日本語サイトについてはこちらをご覧ください。またご導入についての相談はこちらのフォームからお気軽にお問い合わせください。